第5章 数字音频与话音编码
5.1 数字音频的相关概念
音频概述
众所周知,声音是通过空气传播的一种连续的波,叫声波。声音的强弱体现在声波压力的大小上,音调的高低体现在声音的频率上。声音用电表示时,声音信号在时间和幅度上都是连续的模拟信号。统计表明,语音的过程是一个近似的短时平稳随机过程,所谓短时,是指在10-30ms的范围。由于语音信号具有这个性质,我们则有可能将语音信号划分为一帧一帧的进行处理。在实用中,一般一帧的宽度为20ms。那么要具体研究语音的各种特征,压缩方法、传输方法等,就要先了解语音的一些基本类型和参数。下面我们就为大家一一介绍。
声音信号的基本参数
最基本的两个参数是频率和幅度。信号的频率是指信号每秒钟变化的次数,用Hz表示。例如,大气压的变化周期很长,以小时或天数计算,一般人不容易感到这种气压信号的变化,更听不到这种变化。对于频率为几Hz到20 Hz的空气压力信号,人们也听不到,如果它的强度足够大,也许可以感觉到。人们把频率小于20 Hz的信号称为亚音信号,或称为次音信号(subsonic);频率范围为20 Hz~20 kHz的信号称为音频(Audio)信号;虽然人的发音器官发出的声音频率大约是80~3400 Hz,但人说话的信号频率通常为300~3000 Hz,人们把在这种频率范围的信号称为话音(speech)信号;高于20 kHz的信号称为超音频信号,或称超声波(ultrasonic)信号。超音频信号具有很强的方向性,而且可以形成波束,在工业上得到广泛的应用,如超声波探测仪,超声波焊接设备等就是利用这种信号。在多媒体技术中,处理的信号主要是音频信号,它包括音乐、话音、风声、雨声、鸟叫声、机器声等。
话音基础
当肺部中的受压空气沿着声道通过声门发出时就产生了话音。普通男人的声道从声门到嘴的平均长度约为17厘米,这个事实反映在声音信号中就相当于在1 ms数量级内的数据具有相关性,这种相关称为短期相关(short-term correlation)。声道也被认为是一个滤波器,这个滤波器有许多共振峰,这些共振峰的频率受随时间变化的声道形状所控制,例如舌的移动就会改变声道的形状。许多话音编码器用一个短期滤波器(short term filter)来模拟声道。但由于声道形状的变化比较慢,模拟滤波器的传递函数的修改不需要那么频繁,典型值在20 ms左右。
压缩空气通过声门激励声道滤波器,根据激励方式不同,发出的话音分成三种类型:浊音(voiced sounds),清音(unvoiced sounds)和爆破音(plosive sounds)。1.浊音
浊音是在声门打开然后关闭时中断肺部到声道的气流所产生的脉冲,是一种称为准周期脉冲(quasi-periodic pulses)激励所发出的音。声门打开和关闭的速率呈现为音节(pitch)的大小,它的速率可通过改变声道的形状和空气的压力来调整。浊音表现出在音节上有高度的周期性,其值在2~20 ms之间,这个周期性称为长期周期性(long-term periodicity)。图4-1表示了某一浊音段的波形,音节周期大约8 ms。
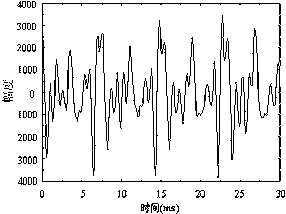
图4-1 浊音段的波形举例
2.清音
清音是由不稳定气流激励所产生的,这种气流是在声门处在打开状态下强制空气在声道里高速收缩产生的,如图4-2所示。

图4-2 清音段的波形举例
3.爆破音
爆破音是在声道关闭之后产生的压缩空气然后突然打开声道所发出的音。
还有一些声音不能归属到上述三种中的任何一种,例如在声门振动和声道收缩同时出现的情况下产生的摩擦音,这种音称为混合音。
虽然各种各样的话音都有可能产生,但声道的形状和激励方式的变化相对比较慢,因此话音在短时间周期(20 ms的数量级)里可以被认为是准定态(quasi-stationary)的,也就是说基本不变的。从上边的图示中不难发现话音信号显示出了高度的周期性,这是由于声门的准周期性的振动和声道的谐振所引起的。而音频编码压缩方法就是利用了这种周期性,这种自然的相关性,来减少数据率而又尽可能不牺牲声音的质量。
语音的基本参数包括基音周期、共振峰、语音谱、声强等。语音生成机构的模型由3部分组成:
1. 声源。声源共有3类:元音、摩擦音、爆破音。元音是由音带的自激振动产生的;摩擦音是靠声道变窄时的气流产生的湍流噪声所产生的;爆破音是由闭合声道突然打开时形成的脉冲波产生的湍流噪声所产生的。
2. 共鸣机构,也称声道。它由鼻腔、口腔与舌头组成。
3. 放射机构。由嘴唇和鼻孔组成,其功能是发出声音并传播出去。
与此语音生成机构模型相对应的声源由基音周期参数描述,声道由共振峰参数描述,放射机构则由语音谱和声强描述。这样,如果我们能够得到每一帧的语音基本参数,我们就不再需要保留该帧的波形编码,而只要记录和传输这些参数,就可以实现数据的压缩。
5.2 音频信号数字化
采样和量化
采样和量化实际上就是一个信源的数字化的过程人类的感官能够觉察且能被大脑解释的信息(如声音、图像等)可以用一个或几个是时间与空间的函数的物理量来描述。这些依赖于时间或空间的物理量可以用仪器来测量,将这些被测量转换为诸如电压、电流等连续的模拟量。由于所有的多媒体信息在计算机内部都是用数字形式描述的,所以要将测量所获取的模拟量信息在计算机内部存储、传输和处理,就有必要将获取的模拟量转换为数字量。这就是信源的数字化。即数字化是一个把模拟信号转化为数字信号的过程。数字化过程需要三步。首先模拟信号必须被采样,这意味着只有离散的值在时间或空间间隔中被保留。其次采样信号被量化,这意味离散的值将出现。在量化之后,并非所有的值都被保留。再将每一个量化值与一组独特的比特相联系,这组比特称为码字。这就是编码过程。
采样
模拟信号是随着时间或(和)空间变化的物理量度,它们能够用下述类型的算术函数来描述:
S=f(t),S=f(x,y,z)或S=f(x,y,z,t)
模拟信号有两个基本性质。首先模拟信号是时间或空间的连续函数,其次模拟信号在任何时间或空间有定义。而计算机仅仅能够处理二进制数字序列。要将这些信号在计算机内存储或传输等,那就要求将模拟信号进行数字化。进行数字化首先要进行采样,采样是在模拟信号的连续量中仅仅保留一组离散的值。采样周期通常是恒定的,换句话说,模拟信号的值通常是在规定的时间或空间间隔中被捕获。设连续信号为f(t),对连续信号采样,即按一定采样时间间隔(T)取值,得到f(nT)(n为整数)。T称采样周期,1/T称为采样频率。称f(nT)为离散信号。采样也被称为时间离散化(例如对声音)或空间离散化(例如对图像)。
在采样的过程中,采样所获取的离散信号f(nT)是从连续信号f(t)上取出的一部分值,显然有已经丢失了一部分值了。现在我们所关心的是用f(nT)能够唯一地恢复出f(t)吗?要使能够唯一地恢复出f(t),这就需要在采样时满足采样定理。
采样定理:
设连续信号f(t)的频谱为f(f),f为频率,以采样间隔T采样得到离散信号f(nT),如果满足:
当![]() ≥f
≥f![]() 时,f
时,f![]() 是截止频率
是截止频率
T≤![]() 或 f
或 f![]() ≤
≤![]()
则可以由离散信号f(nT)完全确定连续信号f(t)。当采样频率等于1/(2T),即f![]() =1/(2T),f
=1/(2T),f![]() 称为Nyquist频率。
称为Nyquist频率。
采样定理告诉我们,用一定速率的离散采样序列可以代替一个连续的频带有限信号而不丢失任何信息,这也是进行数据压缩的一个基本前提。同时传输连续信号问题可归结为传输有限速率的样值问题,这就构成了数字信息传输的基本原理。但值得注意的是,以上所述只是理想的采样,对于实际的混叠噪声;由于实际采样脉冲不可能是理想的冲激函数而引起的孔径失真;由于无穷项的内插公式和理想的内插滤波器不可实现而混入的插入噪声;以及因解码端再生采样脉冲有抖动时而导致的定时抖动失真等。
另外,声音采样的样本大小是用每个声音样本的位数bit/s(即bps)表示的,它反映度量声音波形幅度的精度。样本位数的大小影响到声音的质量,位数越多,声音的质量越高,而需要的存储空间也越多;位数越少,声音的质量越低,需要的存储空间越少。采样精度的另一种表示方法是信号噪声比,简称为信噪比(signal-to-noise ratio, SNR)。
量化
模拟信号采样后,得到一组离散的值。而要完成数字化,还需把采集到的信号转化为能用有限位数表示的信号——即进行量化,也称为振幅离散化,最后将这组值进行编码。
在采样后,为何要进行量化?为了说明这一重要的思想,可以想象一个模拟电信号:它的值随着时间在0mV到+255mV之间连续变化。采样后,设想每一个采样值被存在8位的字节中(8位的计算机芯片),且该值被编码为正整数。采样值被严格限定在0到255之间的256个整数值内,而不是其间的任一个实数值。这个过程就是一个简单形式的量化,如图2-1所示:
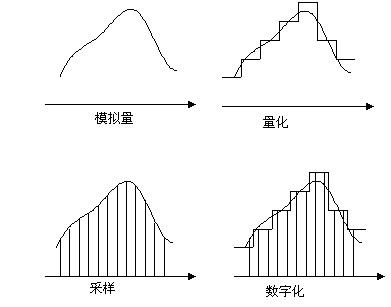
图2-1 数字化过程
以上阐述了量化的思想,量化要完成的功能是按一定的规则对采样值作近似表示,使经量化输出幅值的大小为有限个数。或者说,量化就是用一组有限的实数集合作为输出,其中每个数代表一群最接近于它的采样值。量化输入值的动态范围很大,需要以多的比特数表示一个数值,量化输出只能取有限个整数,称作量化级,希望量化后的数值用较少的比特数便可表示。每个量化输入被强行归一到与其接近的某个输出,即量化到某个级。量化处理总是把一批输入,量化到一个输出级上,所以量化处理是一个多对一的处理过程,是个不可逆的过程,量化处理中有信息丢失,或者说,会引起量化误差(量化噪声)。
量化器即可以用于采样的信号的量化,也可以用于参数或系数的量化,还可以量化信号的的时间或空间样本。
1 标量量化
量化分为标量量化和向量量化。标量量化是对单个样本或单个参数的幅值进行量化,可以理解为一个数一个数地进行量化。
均匀量化
如果采用相等的量化间隔对采样得到的信号或者其他来源的输入作量化,那么这种量化称为均匀量化,也叫做线性量化。如图2-2所示。量化后的样本值Y和原始值X的差E=Y-X称为量化误差或量化噪声。当输入超出了最大值或最小值,量化器就称为过载。若输入在设计的最大最小值范围内,量化误差在均匀量化间隔的一半的范围内,这样的量化误差称为颗粒噪声。
均匀量化的优点是简单。
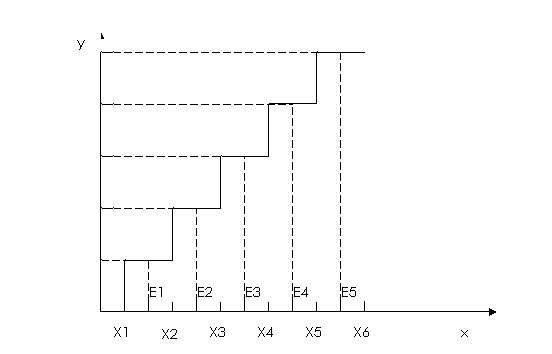
图2-2 均匀量化
如图 2.10所示,x是采样输入的样本值,y是量化后输出的数据。设预测误差的值域为[X1,X6],量化器的判决电平为 {Xi|i=1,…,6},输出的量化电平为{Ei|i=1,…,5},量化过程可以用以下关系式表示:
Q[x]=Ei 如果Xi<x<=Xi+1, i=1,2,…,6 (2.1)
由于量化的间隔,即Xi(i=1,2……,6)之间的间隔是相等,所以称之为均匀量化。
非均匀量化
均匀量化无论对大的输入值还是小的输入值一律都采用相同的量化间隔。为了适应幅值大的输入,同时又要满足精度要求,就需要增加样本的位数。但是,需要量化的数据各有不同的特点,若幅值大的输入并不多,增加的样本位数就没有充分利用。例如,对于DPCM差分预测编码方法中的预测误差这样的信号而言,其幅值的概率分布大部分就集中在“0”附近,为了克服这个不足,就出现了非均匀量化的方法,这种方法也叫做非线性量化。
非线性量化的基本想法是,对概率密度大的区域细量化,对概率密度小的区域粗量化,显然,它与均匀量化相比,在相同的量化分层条件息,其量化误差的均方值要小得多;或者,在同样的均方误差条件下,它只需要比均匀量化器更少的分层。图2-3是非线性量化的原理图。
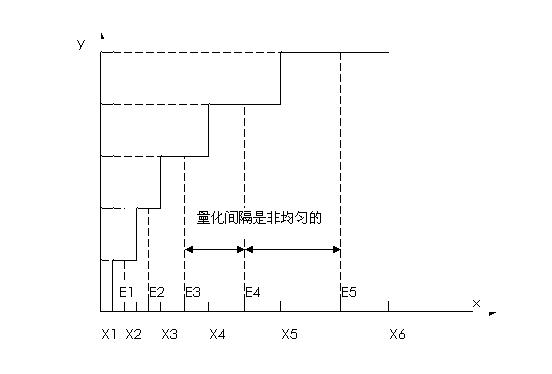
图2-3 非均匀量化
2 向量量化
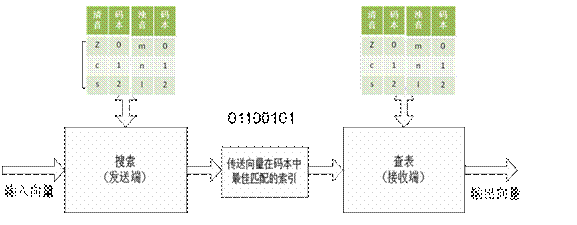
若对这些数据分组,每组K个数构成一个K维向量,然后以向量为单元,逐个向量进行量化,称为向量量化,VQ。
向量量化的原理大致如下:
将实际流分成向量块;
在编码和译码端都有一个称为码本的表,它是模式的集合,每个模式为8位字节。该码本可预定义也可动态构造;
各向量可参考码本选择最佳匹配模式;
一旦找到最佳匹配模式就将码本中的对应条目进行传送;
在接收端,根据传送的索引在接收端码本查出对应的向量。
简单地说,向量量化地原理可归结如下:
比特流被划分为向量。它不传送实际数据,而是传送码本中查到地最佳匹配模式对应的索引。如图2-4所示为向量量化的原理图:
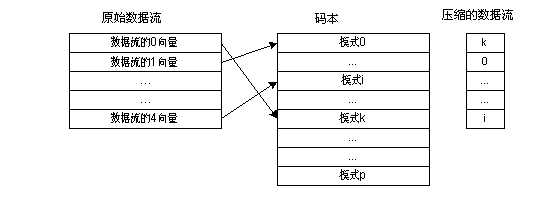
图2-4 向量量化编码的基本原理
如图2-5所示为向量量化的编码解码框图:

图2-5 向量量化的编码解码框图
如果出现实际值与模式根本不匹配,那在接收端就会出现失真。为了对此进行补救,该技术要计算一下实际值和模式的差分。然后将该差分与模式的参数一起传送。参数编码可用自身进行量化。因此,根据传送是否有差分以及差分为多大,向量量化可能是无损的或是有损的压缩模式。
语音质量及清晰度
为了确定语音编码器的性能,需要对编码器生成的语音进行清晰度和质量的测量。质量这个概念则是指语音听起来有多自然,清晰度这个概念则通常是指输出语音是否容易听清楚。一个编码器有可能生成高清晰度但品质很差的语音,声音听起来像是机器发生的,不能辨认出说话者是谁。在另一方面,一个不清晰的语音是不可能成为高品质的,却存在着很悦耳的声音却很模糊的情况,这种现象的一个例子就是,为一个增量调制器在处理低通滤波器频限过低的声音时,调制器的输出就属于上面的那种现象。滤波造成了清晰度的损失,但对高频的抑制却使得声音非常悦耳。
尽管许多技术的应用能客观上评价语音编码器的性能,比如说,信噪比和谱失真测量,在最初的评价上很有用,但语音编码器质量或清晰度的最终判断还是需要通过人的感觉器官来测试。不过,既然如此信赖这个测试结果,那么就要很谨慎的对待主观试听测试的设计了。
对于每个语音编码的测试,都必须仔细的挑选发音,以保证各种语音都能够有所体现,例如,有一些编码器在语音处理上很不错,但在清音的再生方面却不太精确,同样,有些编码器在低频声音上性能要优于高频声音,因此,就要慎重的选择能代表现实环境的做实验的说话者,有女声也有男声,做实验的听众也必须处于一般用户的环境下。最终,让听众听到的发音要以一定的顺序,不能对结果造成某种偏重的影响。
声音质量与数据
根据声音的频带,通常把声音的质量分成5个等级,
由低到高分别是电话(telephone)、调幅(amplitude modulation,AM)广播、调频(frequency modulation,FM)广播、激光唱盘(CD-Audio)、数字录音带(digital audio tape,DAT)的声音。
声音文件的存储格式
| 文件的扩展名 | 说 明 |
|---|---|
au |
Sun和NeXT公司的声音文件存储格式(8位μ律编码或者16位线性编码) |
aif(Audio Interchange) |
Apple计算机上的声音文件存储格式 |
cmf(Creative Music Format) |
声霸(SB)卡带的MIDI文件存储格式 |
mct |
MIDI文件存储格式 |
mff(MIDI Files Format) |
MIDI文件存储格式1/2 |
mid(MIDI) |
Windows的MIDI文件存储格式 |
mp2 |
MPEG Layer I , II |
mp3 |
MPEG Layer III |
文件的扩展名 |
说 明 |
mod(Module) |
MIDI文件存储格式 |
rm(RealMedia) |
RealNetworks公司的流放式声音文件格式 |
ra(RealAudio) |
RealNetworks公司的流放式声音文件格式 |
rol |
Adlib声音卡文件存储格式 |
snd(sound) |
Apple计算机上的声音文件存储格式 |
seq |
MIDI文件存储格式 |
sng |
MIDI文件存储格式 |
voc(Creative Voice) |
声霸卡存储的声音文件存储格式 |
wav(Waveform)* |
Windows采用的波形声音文件存储格式 |
wrk |
Cakewalk Pro软件采用的MIDI文件存储格式 |
常见的声音文件扩展名
*支持PCM,ADPCM,μ率和A率波形
声音工具
1. Windows 95/98本身带的“Sound Recorder—录音机”
当你在Windows XP的界面上单击:开始→程序→附件→娱乐→单击“录音机”之后就出现如图所示的窗口。 使用它可录音,作简单的声音编辑(如插入、删除等)。
图 Windows的录音器
2. 买声音卡时带的工具
如果你的计算机安装有声音卡,一般来说都附带有声音工具。例如,声霸(Sound Blaster)卡带有几种声音工具,通常要由用户自己安装。 其中,功能比较强的是WaveStudio。
图 Creative Wave Studio Version 4.00的用户界面
3. 网络上下载的工具
因特网上有许多站点提供试用的或者是免费的声音工具。
图所示的就是从http://www.syntrillium.com上下载供试用的Cool Edit工具,它很受声音研究工作者的欢迎。 类似的工具还有goldwave公司的声音工具,网址:http://www.goldwave.com,Cakewalk,Cubase等。
图 Cool Edit 96的用户界面
语音编码器评估的阶段
当开发出一种语音编码器时,要陆续采用非正式的主客观测试和正式主观测试来评价其性能,非正式客观测量是最初的检验,比如信噪比或频谱距测量等等。只要当这些客观值都达到要求后,就可以进行非正式主观测试,比如原始语音的相互比较,以及各种编码器之间相互比较。如果这些结果都能通过,编码器的开发者就可以进行正式主观测试了,这就可以得到性能的指标。这些步骤很费时,而且开销很大,所以,最后一步,正式测试,同前面两步非正式测试比较起来,用得要少一些。
非正式测试
面我们将简单介绍一下客观测试的计算,比如信噪比和频谱间距,再讨论一下非正式主观测试,这些测试都没有经过严格的约定,所以很容易被错误的解释,但对于有经验的语音编码研究人员来说,还是很有用的。
客观测量
波形编码器性能的一种最容易的计算方式就是信噪比(SNR),它可以用下式表示:
 (1.1)
(1.1)
其中S(n)是输入语音,![]() 是输出语音,<·>表示整个发音的时间平均,片断SNR经常用来代表语音输入的主观性能。可以对许多不相互重叠的数据块采用方程(1.1)来计算SNR,然后对这些数据块取算术平均值,因此,Jayant和Noll(1984)令SNRBj代表第j个数据块的SNR,对于K个数据块,
是输出语音,<·>表示整个发音的时间平均,片断SNR经常用来代表语音输入的主观性能。可以对许多不相互重叠的数据块采用方程(1.1)来计算SNR,然后对这些数据块取算术平均值,因此,Jayant和Noll(1984)令SNRBj代表第j个数据块的SNR,对于K个数据块,
![]() (1.2)
(1.2)
SNR和SNRSEG可以排列出编码器的性能,但是,这些差异在感观上的区别有多大,仍然不清楚。而且,用SNR和SNRSEG来比较PCM和DPCM会得到完全错误的结论。
Itakura(1975)引入了一种频谱间距测量,可以从LPC的系数计算得到:
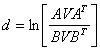 (1.3)
(1.3)
其中行向量A和B是扩展的预测器系数向量。![]() 和
和![]() ,系数ak可以从语音编码器的输入语音中计算出来,系数bk可以从语音编码器的输出语音中计算出来,V是语音编码器输出的自相关矩阵,
,系数ak可以从语音编码器的输入语音中计算出来,系数bk可以从语音编码器的输出语音中计算出来,V是语音编码器输出的自相关矩阵,![]() ,并且,按照Sambur和Jayant(1976)的论断,
,并且,按照Sambur和Jayant(1976)的论断,![]() 意味着输入语音的频谱与语音编码器输出的语音差别很大。
意味着输入语音的频谱与语音编码器输出的语音差别很大。
另一种频谱间距测量可以采用下式
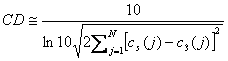 (1.4)
(1.4)
其中![]() 和
和![]() 分别为输入语音和编码器输出语音的倒对数频谱系数(cepstral coefficient。),倒对数频谱系数是能量谱对数的反傅立叶变换,但我们仍可以从 LPC系数
分别为输入语音和编码器输出语音的倒对数频谱系数(cepstral coefficient。),倒对数频谱系数是能量谱对数的反傅立叶变换,但我们仍可以从 LPC系数![]() 中计算出:
中计算出:
![]() (1.5)
(1.5)
![]() ,一个大约为0.5dB的CD值相当于8位μ律PCM的性能,CD值越大,性能越差。
,一个大约为0.5dB的CD值相当于8位μ律PCM的性能,CD值越大,性能越差。
主观测试
听觉测试是对比两个语音编码器的最有效的方式之一,这样的测试相对来说比较容易进行,但是只有两个相互参照的结果。我们不能指出这两种编码器性能有多相近,但是如果两种编码失真的类型不一样,对于听众来说,要说出哪一种更好就困难了。当一种编码器与8位μ律PCM相比较时,如果编码器在性能上不是相等的话,就很难确切地说出它们在性能上究竟有多相近。另外,当一个δ调制器与一个子带编码器比较时,δ调制器可能存在“嘶嘶”的噪音,而子带编码器可能有回响声,这时,试听者作出的优劣判断就会根据哪种失真是他所讨厌的,完全由试听者个人的好恶来确定,这就不是一个可靠的性能指标。可是,这种对比试听的测试现在仍然广泛地使用着。
对于一些专门设备,如蜂窝通信或声音邮件,让用户在尽可能接近自然环境的条件下,真正地实验这种编码器,会更有利一些。这种方法的优点是不需采用短的、有记录的、没有代表性的语音片断来进行评价合成语音。换句话说,用户会更加关心系统是否能达到预定目标,而不是去听输出语音的“问题”出在哪儿,这意味着要有一个完全真实的系统,比较难实现。
正式测试
有许多正式测试过程用于评定语音编码器的清晰度和品质,可分为清晰度测试和品质测试,然而,有些测试可以同时测量这两项。
清晰度
诊断押韵测试(DRT)是由Voiers(1977)发明的,是为了测试编码器的清晰度,韵律测试试听者必须区分出一对押韵词的音节。就是说,试听者要分辨出一对词比如meat-beat, pool-tool, saw-thaw, caught-taught等等,每一对词的六种声音特征中只有一种不同,并且,试听者只会听到这一对词中的一个词,然后就要确定是读的哪一个词,最后的DRT得分是按下式计算得到的百分数:
![]() (1.6)
(1.6)
其中R是正确选择的数量,W是选择错误的数目,T是总共测试的单词对的数目,通常,![]() ,良好的清晰度得分为90(Papamichalis 1987),关于结果详细列表是由Dynastat(Papamichalis 1987)做的。
,良好的清晰度得分为90(Papamichalis 1987),关于结果详细列表是由Dynastat(Papamichalis 1987)做的。
还有一种测试是Dynastat提出的,叫做改进的押韵测试(MRT),在MRT中试听者要求去辨别六个词中的一个,这六个词可以是首音节或末音节不同。但是MRT现在用得不多。
质量
发音指数(AI)是一种声音品质的客观衡量方法,它起源于1947年,现在仍然经常使用。AI是一种以频率为权重的信噪比计算法。把200Hz到6100Hz范围的频率分成20个带宽不等的子段,如表A.1所示,对每个子段计算其信噪比,SNR的值极限为30DB,标准化至1,并平均化,可得:
![]() (1.7)
(1.7)
需要注意的是,要将语音限制在电话频段,即200~3200Hz,会将AI降至90%或0.90。AI应用的主要障碍就是20个带通滤波器很复杂。
对一种编码器给出一个平均评价分(Mean Opinion Score,MOS),试听者要把语音编码器的输出分为优(5)、良(4)、中(3)、差(2)、劣(1),试听者可以根据主观感受到的失真把编码语音分类为下面几类:察觉不到(5),能稍稍察觉到但无不适感(4),能察觉且有不适感(3),有不适感但还能忍受(2),很不适且无法忍受(1)。
括号里的数字是用来给主观评价记下分值,所有试听者的分数等级要进行平均以给出编码器的MOS。分数等级的标准差需要计算多次,以确定估计所得到的MOS的适用性。 MOS为4.0~4.5通常是指高品质,例如8位μ=255 log-PCM最近的MOS为4.5,标准差大约为0.6。
表1-3
编号 范围 意义 编号 范围 意义
1 200~330 270 11 1660~1830 1740
2 330~430 380 12 1830~2020 1920
3 430~560 490 13 2020~2240 2130
4 560~700 630 14 2240~2500 2370
5 700~840 770 15 2500~2820 2660
6 840~1000 920 16 2820~3200 3000
7 1000~1150 1070 17 3200~3650 3400
8 1150~1310 1230 18 3650~4250 3950
9 1310~1480 1400 19 4250~5050 4650
10 1480~1660 1570 20 5050~6100 5600
因为大的方差意味着测试的不可靠,所以计算MOS值的方差很重要。如果试听者没有弄清楚分类的意义就可能出现大的方差。有时候,可以把好的语音和坏的语音例子让试听者先听一下,然后再开始测试打分。研究表明,在同样的线路条件下,在不同国家用本土语言,试听者不容易在等级定位上取得相互一致。就是说MOS需要进行调整以得到可靠的品质指标 (Goodman和Nash 1982)。各种语音编码器的MOS和噪声条件由Daumer(1982)给出。
诊断可接受度衡量(Diagnostic Acceptability Measure, DAM)是由Dynastat (Voiers1977) 开发的,它可以更加系统地衡量语音品质,对于DAM来说,关键是试听者要经过高度训练,并要反复校对已得到一个平均结果。试听者每人都要听一组句子,这些句子是从哈佛1965年的发音平衡句子表中选出的,比如“Cats and dogs each hate the other”(猫和狗彼此憎恨)和“The pipe began to rust while new”(管子还是新的时候就开始生锈了)。这些句子由被测的语音编码器进行处理。试听者要从信号品质,背景品质,总体效果三个特征方面给出1~100之间的一个分数,每个特征的等级都要加权并用于多重非线性回归,最后,进行调整以弥补试听者听力造成的不足之处,典型的得分都在45~55%,50%表示这个系统“好”。
调制噪声参考单元(Modulated noise reference unit, MNRU)意见均衡Q近来用得很多,因为它在ITU-T推荐书的波形编码器评价(CCITT 1984;Kitawaki和Nagabuchi 1988)中显出很好的特征。在成对的比较或意见测试中,编码语音要同一种参考信号进行比较,这种参考信号带有一定程度的语音相关噪声,是由MNRU系统产生的,其比较见图A.1(CCITT 1984,1988)。参考信号有着不同的信号一语音相关噪声比,这由Q值表示,可以通过调整衰减器/放大器的相对增益来获得。Q值表示编码语音和MNRU输出的主观匹配是一种很好的量化性能指标。存在窄频段和宽频段的MNRU系统,窄段Q记作QN。这是一种衡量波形编码器语音性能的相当精确的方法,因为MNRU失真能模仿波形编码器的噪声,对于编码器其它形式的失真,这可能用处不大。
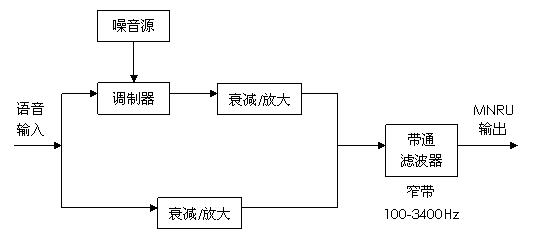
图1-2 MNRU系统框图
重要因素
这里还有一些对于所有语音编码器性能测试都很重要的因素,第一,必须有足够的测试者,他们的声音特征要非常丰富,能够有广泛的代表性。第二,用来测试的数据要足够多,尽可能的包括所有的可能性,在一些设计很好的测试当中,如DRT和DAM,语音材料是固定的,对于说话者的类型和数量也大致是有指导性要求的,在这些测试中,上述的两点不会引起争议。然而AI,MOS对于和一些面对面的比较,就没有规定要多少说话者和多少数据才算足够,当然是“越多越好”。有一种方法是考察最新的说话者和材料,直到没有新的失真出现为止。虽然这个方法看起来是无止境的,但对于熟悉语音编码的人来说还是很有用的。第三点就是对于大部分应用来说,品质和清晰度都很重要,两点都应该测试,通常,很悦耳的语音就不用评价其清晰度了。
5.3 话音编码技术与分类
音源编码
音源编译码器
音源编译码的想法是企图从话音波形信号中提取生成话音的参数,使用这些参数通过话音生成模型重构出话音。针对话音的音源编译码器叫做声码器(vocoder)。在话音生成模型中,声道被等效成一个随时间变化的滤波器。每隔10~20 ms更新一次。
这种声码器的数据率在2.4 kb/s左右,产生的语音虽然可以听懂,但其质量远远低于自然话音。
音源编码特性
当肺部中的受压空气沿着声道通过声门发出时就产生了话音。普通男人的声道从声门到嘴的平均长度约为17厘米,这个事实反映在声音信号中就相当于在1 ms数量级内的数据具有相关性,这种相关称为短期相关(short-term correlation)。
声道也被认为是一个滤波器,这个滤波器有许多共振峰,这些共振峰的频率受随时间变化的声道形状所控制,例如舌的移动就会改变声道的形状。许多话音编码器用一个短期滤波器(short term filter)来模拟声道。但由于声道形状的变化比较慢,模拟滤波器的传递函数的修改不需要那么频繁,典型值在20 ms左右。
压缩空气通过声门激励声道滤波器,根据激励方式不同,发出的话音分成三种类型:
浊音(voiced sounds)
清音(unvoiced sounds)
爆破音(plosive sounds)。
语音的基本参数包括基音周期、共振峰、语音谱、声强等。语音生成机构的模型由3部分组成:
1. 声源:共有3类--元音、摩擦音、爆破音。
元音是由音带的自激振动产生的;
摩擦音是靠声道变窄时的气流产生的湍流噪声所产生的;
爆破音是由闭合声道突然打开时形成的脉冲波产生的湍流噪声所产生的。
2. 共鸣机构,也称声道。它由鼻腔、口腔与舌头组成。
3. 放射机构,由嘴唇和鼻孔组成,其功能是发出声音并传播出去。
与此语音生成机构模型相对应的声源由基音周期参数描述,声道由共振峰参数描述,放射机构则由语音谱和声强描述。这样,如果我们能够得到每一帧的语音基本参数,我们就不再需要保留该帧的波形编码,而只要记录和传输这些参数,就可以实现数据的压缩。
音源编码器的工作原理示意图
波形编译码器
波形编译码的想法是,不利用生成话音信号的任何知识而企图产生一种重构信号,它的波形与原始话音波形尽可能地一致。一般来说,这种编译码器的复杂程度比较低,数据速率在16 kb/s以上,质量相当高。低于这个数据速率时,音质急剧下降。
最简单的波形编码是脉冲编码调制(pulse code modulation,PCM),它仅仅是对输入信号进行采样和量化。
典型的窄带话音带宽限制在4kHz,采样频率是8 kHz。如果要获得高一点的音质,样本精度要用12位,它的数据率就等于96 kb/s,这个数据率可以使用非线性量化来降低。
例如,可以使用近似于对数的对数量化器(logarithmic quantizer),使用它产生的样本精度为8位,它的数据率为64 kb/s时,重构的话音信号几乎与原始的话音信号没有什么差别。
在北美的压扩(companding)标准是μ律(μ-law),在欧洲的压扩标准是A律(A-law)。它们的优点是编译码器简单,延迟时间短,音质高。但不足之处是数据速率比较高,对传输通道的错误比较敏感。
在话音编码中,一种普遍使用的技术叫做预测技术,这种技术是企图从过去的样本来预测下一个样本的值。这样做的根据是认为在话音样本之间存在相关性。如果样本的预测值与样本的实际值比较接近,它们之间的差值幅度的变化就比原始话音样本幅度值的变化小,因此量化这种差值信号时就可以用比较少的位数来表示差值。这就是差分脉冲编码调制(differential pulse code modulation,DPCM)的基础—对预测的样本值与原始的样本值之差进行编码。
这种编译码器对幅度急剧变化的输入信号会产生比较大的噪声,改进的方法之一就是使用自适应的预测器和量化器,这就产生了一种叫做自适应差分脉冲编码调制(adaptive differential PCM,ADPCM)。
上述的所有波形编译码器完全是在时间域里开发的,在时域里的编译码方法称为时域法(time domain approach)。在开发波形编译码器中,人们还使用了另一种方法,叫做频域法(frequency domain approach)。例如,在子带编码(sub-band coding,SBC)中,输入的话音信号被分成好几个频带(即子带),变换到每个子带中的话音信号都进行独立编码。
子带编码SBC
混合编译码
混合编译码的想法是企图填补波形编译码和音源编译码之间的间隔。波形编译码器虽然可提供高话音的质量,但数据率低于16 kb/s的情况下,在技术上还没有解决音质的问题;声码器的数据率虽然可降到2.4 kb/s甚至更低,但它的音质根本不能与自然话音相提并论。为了得到音质高而数据率又低的编译码器,历史上出现过很多形式的混合编译码器,但最成功并且普遍使用的编译码器是时域合成-分析(analysis-by-synthesis,AbS)编译码器。
三种话音编译码器
通常把已有的话音编译码器分成以下三种类型:波形编译码器(waveform codecs),音源编译码器(source codecs)和混合编译码器(hybrid codecs)。一般来说,波形编译码器的话音质量高,但数据率也很高;音源编译码器的数据率很低,产生的合成话音的音质有待提高;混合编译码器使用音源编译码技术和波形编译码技术,数据率和音质介于它们之间。
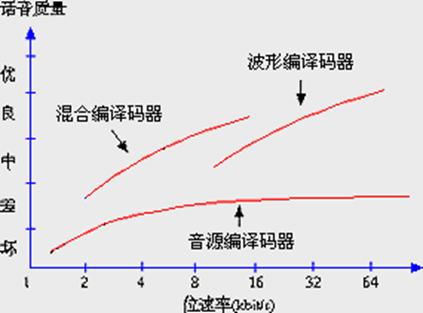
图 三种普通编译码器的音质与数据率
编码器 |
MOS分 |
|---|---|
64 kb/s脉冲编码调制(PCM) |
4.3 |
32 kb/s自适应差分脉冲编码调制(ADPCM) |
4.1 |
16 kb/s低时延码激励线性预测编码(LD-CELP) |
4.0 |
8 kb/s码激励线性预测编码(CELP) |
3.7 |
3.8 kb/s码激励线性预测编码(CELP) |
3.0 |
2.4 kb/s线性预测编码(LPC) |
2.5 |
表 部分编码器的MOS分
子带编码(SBC)
人耳对声音信号的判断是与信号频率有关的。例如人耳对1kHz频率的信号尤其敏感。有实验结果表明,如果人发出无意义的音节,如果只保留400Hz到6kHz频率范围的语音信号,那么听话人就可以听清此音节;如果把上限降至1.7kHz则可听清一半;如果要听清连续有意义的句子,那么只要保留频率在400~3000Hz左右,语音就可以完全听懂。与人耳听觉特性在频率上发布不均匀相对应,人所发出的语音信号的频率也不是平坦的。事实上多数人的语音能量,主要集中在频率范围500~1000Hz左右,并随着频率的升高很快衰减。
根据上述特性可以将输入信号用某种方法划分成不同频段上的子信号,然后区别对待。根据各子信号的特性,分别编码。比如对语音信号能量大的、比较集中的、对听觉有重要影响的分配较多的码字,次要信号则分配较少的码字。各子信号分别编码后的码字被传送到接收方,再被分别解码,最后合成出相应的解码语音。
于是就产生了子带编码(subband coding,SBC),概括的来说子带编码的基本思想是:使用一组带通滤波器(band-pass filter,BPF)把输入音频信号的频带分成若干个连续的频段,每个频段称为子带。与音源特定编码法不同,SBC的编码对象不局限于话音数据,也不局限于哪一种声源。这种方法是首先把时域中的声音数据变换到频域,对频域内的子带分量分别进行量化和编码,根据心理声学模型确定样本的精度,从而达到压缩数据量的目的。在信道上传送时,将每个子带的代码复合起来。在接收端译码时,将每个子带的代码单独译码,然后把它们组合起来,还原成原来的音频信号。子带编码的方块图如图5-3所示,图中的编码/译码器,可以采用ADPCM,APCM,PCM等。

图5-3 子带编码方块图
采用对每个子带分别编码的好处有二个。第一,对每个子带信号分别进行自适应控制,量化阶(quantization step)的大小可以按照每个子带的能量电平加以调节。具有较高能量电平的子带用大的量化阶去量化,以减少总的量化噪声。第二,可根据每个子带信号在感觉上的重要性,对每个子带分配不同的位数,用来表示每个样本值。例如,在低频子带中,为了保护音调和共振峰的结构,就要求用较小的量化阶、较多的量化级数,即分配较多的位数来表示样本值。而话音中的摩擦音和类似噪声的声音,通常出现在高频子带中,对它分配较少的位数。
音频频带的分割可以用树型结构的式样进行划分。首先把整个音频信号带宽分成两个相等带宽的子带:高频子带和低频子带。然后对这两个子带用同样的方法划分,形成4个子带。这个过程可按需要重复下去,以产生2K个子带,K为分割的次数。用这种办法可以产生等带宽的子带,也可以生成不等带宽的子带。例如,对带宽为4000 Hz的音频信号,当K=3时,可分为8个相等带宽的子带,每个子带的带宽为500 Hz。也可生成5个不等带宽的子带,分别为[0,500],[500,1000],[1000,2000],[2000,3000]和[3000,4000]。
把音频信号分割成相邻的子带分量之后,用2倍于子带带宽的采样频率对子带信号进行采样,就可以用它的样本值重构出原来的子带信号。例如,把4000 Hz带宽分成4个等带宽子带时,子带带宽为1000 Hz,采样频率可用2000 Hz,它的总采样率仍然是8000 Hz。
由于分割频带所用的滤波器不是理想的滤波器,经过分带、编码、译码后合成的输出音频信号会有混迭效应。据有关资料的分析,采用正交镜象滤波器(quandrature mirror filter,QMF)来划分频带,混迭效应在最后合成时可以抵消。
图4-4表示用QMF分割频带的子带编译码简化框图。图中把全带宽音频信号分割成两个等带宽子带的情况。HH(n)和HL(n)分别表示高通滤波器和低通滤波器,它们组成一对正交镜象滤波器。这两个滤波器也叫做分析滤波器。图5-4(b)是QMF简化的幅频特性。 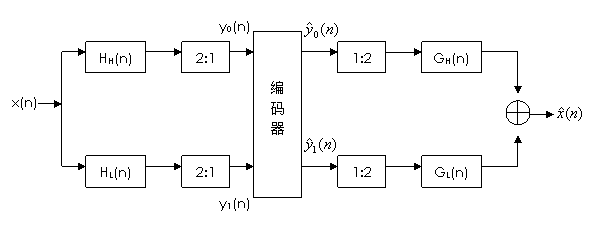 (a) QMF分割频道方框图
(a) QMF分割频道方框图
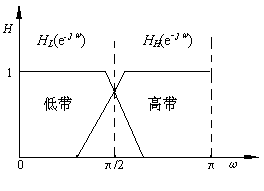
(b) QMF幅频特性简化图
图5-4 采用QMF的子带编译码简化框图
子带编码器SBC愈来愈受到重视。在中等速率的编码系统中,SBC的动态范围宽、音质高、成本低。使用子带编码技术的编译码器已开始用于话音存储转发(voice store-and-forward)和话音邮件,采用2个子带和ADPCM的编码系统也已由CCITT作为G.722标准向全世界推荐使用。MPEG-1的音频标准也使用子带编码来达到既压缩声音数据又尽可能保留声音原有质量的目的。
语音子带编码
1976年Crochiere, Webber和Flanagan引进了语音子带编码的方法,如图5-5所示。这种编码器的基本操作步骤如图5-6:原始声音通过带通滤波分解为许多子频带,每个子频带独立进行低通转换、数字化和编码。在接收端,信号通过内插恢复原始的抽样率,通过调制恢复到原来的频带,这样各个频带的分量相合成以得到重构的语音信号。
如图5-5和5-6所示,整带采样(Crochiere, Webber和Flanagan 1976)可以避免由频率转换而引起调制工作。整带采样中带宽为Wn的第n个子带有较低的截止频率mWn和较高的截止频率(m+1)Wn(m为整数)。因为一个子带的最低频率与此子带的带宽之比是一个整数,即![]() ,并且频率为2Wn的采样不会造成多余的频谱,子带n的频谱副本频率大约为0,因此我们可以不用调制就可以进行频率转换。
,并且频率为2Wn的采样不会造成多余的频谱,子带n的频谱副本频率大约为0,因此我们可以不用调制就可以进行频率转换。
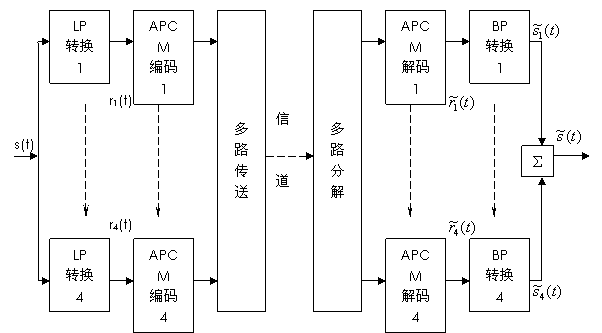
图5-5 四子带编码器

图5-6 最初的子带编码器的基本操作
子带编码中还有三个关键操作,分别是:子带滤波,子带间比特分配和子带编码。理想情况下,所有子带之和可以覆盖整个信号带宽,而不会重叠。但实际的滤波器的下降速度有限,因此这种理想情况不会发生。如果子带滤波后的各频带重叠太多,将会需要更大的比特律,原来各个独立子带的误差也会影响相邻的子带,造成一种混淆现象。早期的解决办法是相邻子带间留有间隔。尽管采取了这些措施,这些间隙仍会引起输出结果的回声现象(Crochiere, Webber和Flanagan 1976)。
语音子带编码的比特分配一般是基于主观试验的,而不利用比特分配的常规方法,这样可以收到最好的效果。通常具有自适应特性的比特分配方法比固定的比特分配方法要好,但必须告知接收者关于特定块的比特分配信息(每个块/帧的部分比特数将用来传输这些信息),所以选择分配方法是常常要受到限制。
每个子带有其自身的解码/编码对,可以采用任何一个标准的编码策略(如自适应性的量化编码,DPCM或向量量化)。我们常采取后向自适应算法避免用部分比特率的方法处理单方(收方或接方)信息。
5.4 脉冲编码调制(PCM)
脉冲编码调制(PCM)
PCM的概念
脉冲编码调制(pulse code modulation,PCM)是概念上最简单、理论上最完善的编码系统,是最早研制成功、使用最为广泛的编码系统,但也是数据量最大的编码系统。
在这个编码框图中,它的输入是模拟声音信号,它的输出是PCM样本。图中的“防失真滤波器”是一个低通滤波器,用来滤除声音频带以外的信号;“波形编码器”可暂时理解为“采样器”,“量化器”可理解为“量化阶大小(step-size)”生成器或者称为“量化间隔”生成器。
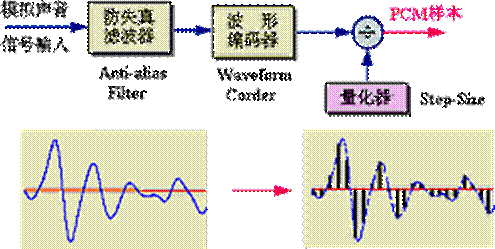
图 PCM编码框图
G.711标准
在这种编码标准中,采用的是非均匀量化的方法。
在非均匀量化中,采样输入信号幅度和量化输出数据之间定义了两种对应关系,一种称为μ律压扩(companding)算法,另一种称为A律压扩算法。其中μ律主要在美国、日本、加拿大等国采用,A律主要是欧洲使用的一种压缩律。
μ律压扩
μ律(μ-Law)压扩(G.711)主要用在北美和日本等地区的数字电话通信中,按下面的式子确定量化输入和输出的关系:
![]()
式中:x为输入信号幅度,规格化成-1<= x<= 1;sgn(x)为x的极性;μ为确定压缩量的参数,它反映最大量化间隔和最小量化间隔之比,取100<=μ<= 500。
由于μ律压扩的输入和输出关系是对数关系,所以这种编码又称为对数PCM。
具体计算时,用μ=255,把对数曲线变成8条折线以简化计算过程。
A律压扩
A律(A-Law)压扩(G.711)主要用在欧洲和中国大陆等地区的数字电话通信中,按下面的式子确定量化输入和输出的关系:
![]() 0 <= |x| <= 1/A
0 <= |x| <= 1/A
![]() 1/A<= |x|<= 1
1/A<= |x|<= 1
式中:x为输入信号幅度,规格化成 -1<= x<= 1;sgn(x)为x的极性;A为确定压缩量的参数,它反映最大量化间隔和最小量化间隔之比。
A律压扩的前一部分是线性的,其余部分与μ律压扩相同。具体计算时,A=87.56,为简化计算,同样把对数曲线部分变成折线。
对于采样频率为8 kHz,样本精度为13位、14位或者16位的输入信号,使用μ率压扩编码或者使用A率压扩编码,经过PCM编码器之后每个样本的精度为8位,输出的数据率为64 kb/s。这个数据就是CCITT推荐的G.711标准:话音频率脉冲编码调制(Pulse Code Modulation (PCM) of Voice Frequencies)。
PCM在通信中的应用
PCM编码早期主要用于话音通信中的多路复用。一般来说,在电信网中传输媒体费用约占总成本的65%,设备费用约占成本的35%,因此提高线路利用率是一个重要课题。提高线路利用率通常用下面两种方法:
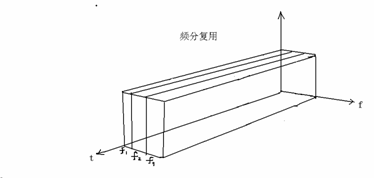
(1) 频分多路复用 (frequency-division multiplexing,FDM)
这种方法是把传输信道的频带分成好几个窄带,每个窄带传送一路信号。例如,一个信道的频带为1400 Hz,把这个信道分成4个子信道(subchannels):820~990 Hz, 1230~1400 Hz, 1640~1810 Hz和2050~2220 Hz,相邻子信道间相距240 Hz,用于确保子信道之间不相互干扰。每对用户仅占用其中的一个子信道。这是模拟载波通信的主要手段。
(2) 时分多路复用(time-division multiplexing,TDM)
这种方法是把传输信道按时间来分割,为每个用户指定一个时间间隔,每个间隔里传输信号的一部分,这样就可以使许多用户同时使用一条传输线路。这是数字通信的主要手段。例如,话音信号的采样频率f=8000 Hz,它的采样周期=125μs,这个时间称为1帧(frame)。在这个时间里可容纳的话路数有两种规格:24路制和30路制。
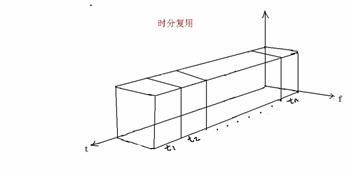
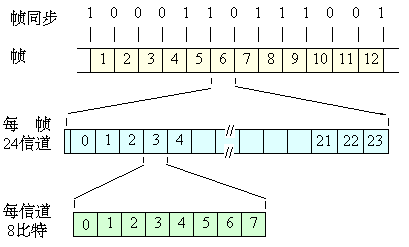
图 24路PCM的帧结构
24路制的重要参数如下:
(1) 每秒钟传送8000帧,每帧125μs。
(2) 12帧组成1复帧(用于同步)。
(3) 每帧由24个时间片(信道)和1位同步位组成。
(4) 每个信道每次传送8位代码,1帧有24 × 8 +1=193位(位)。
(5) 数据传输率R=8000×193=1544 kb/s。
(6) 每一个话路的数据传输率=8000×8=64 kb/s。
30路制的重要参数如下:
(1) 每秒钟传送8000帧,每帧125μs。
(2) 16帧组成1复帧(用于同步)。
(3) 每帧由32个时间片(信道)组成。
(4) 每个信道每次传送8位代码。
(5) 数据传输率:R=8000×32×8=2048 kb/s。
(6) 每一个话路的数据传输率=8000×8=64 kb/s。
时分多路复用(TDM)技术已广泛用在数字电话网中,为反映PCM信号复用的复杂程度,通常用“群(group)”这个术语来表示,也称为数字网络的等级。PCM通信方式发展很快,传输容量已由一次群(基群)的30路(或24路),增加到二次群的120路(或96路),三次群的480路(或384路),……。
下图是二次复用的示意图。图中的N表示话路数,无论N=30还是N=24,每个信道的数据率都是64 kb/s,经过一次复用后的数据率就变成2048 kb/s(N=30)或者1544 kb/s(N=24)。在数字通信中,具有这种数据率的线路在北美叫做T1远距离数字通信线,提供这种数据率服务的级别称为T1等级,在欧洲叫做E1远距离数字通信线和E1等级。T1/E1,T2/E2,T3/E3,T4/E4和T5/E5的数据率如表3-02所示。请注意,上述基本概念都是在多媒体通信中经常用到的。
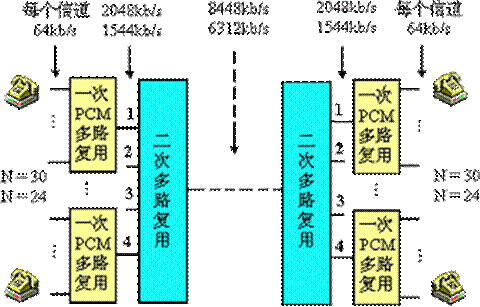
图 二次复用示意图
表 多次复用的数据传输率
数字网络等级 |
T1/E1 |
T2/E2 |
T3/E3 |
T4/E4 |
T5/E5 |
|
美国 |
64 kb/s话路数 |
24 |
96 |
672 |
4032 |
|
|
总传输率(Mb/s) |
1.544 |
6.312 |
44.736 |
274.176 |
|
|
数字网络等级 |
1 |
2 |
3 |
4 |
5 |
欧洲 |
64 kb/s话路数 |
30 |
120 |
480 |
1920 |
7680 |
|
总传输率(Mb/s) |
2.048 |
8.448 |
34.368 |
139.264 |
560.000 |
日本 |
64 kb/s话路数 |
24 |
96 |
480 |
1440 |
|
|
总传输率(Mb/s) |
1.544 |
6.312 |
32.064 |
97.728 |
|
5.5 自适应差分脉冲编码调制
G.711使用A律或μ律PCM方法对采样率为8 kHz的声音数据进行压缩,压缩后的数据率为64 kb/s。
为了提高充分利用线路资源,而又不希望明显降低传送话音信号的质量,就要对它作进一步压缩,方法之一就是采用ADPCM。
自适应脉冲编码调制(APCM)的概念
自适应脉冲编码调制(adaptive pulse code modulation,APCM)是根据输入信号幅度大小来改变量化阶大小的一种波形编码技术。 这种自适应可以是瞬时自适应,即量化阶的大小每隔几个样本就改变,也可以是音节自适应,即量化阶的大小在较长时间周期里发生变化。
例如,自适应增量调制就是自适应技术的一种应用。
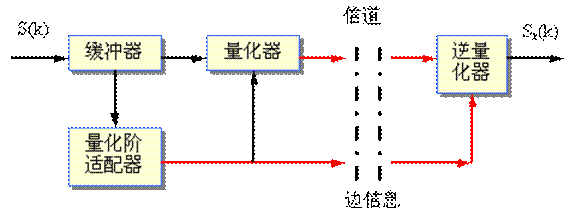
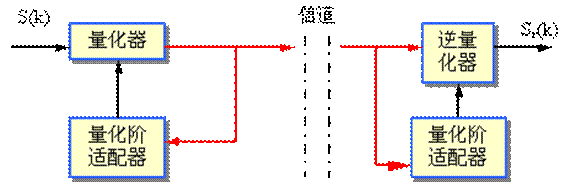
改变量化阶大小的方法有两种:一种称为前向自适应(forward adaptation);另一种称为后向自适应(backward adaptation)。前者是根据未量化的样本值的均方根值来估算输入信号的电平,以此来确定量化阶的大小,并对其电平进行编码作为边信息(side information)传送到接收端。后者是从量化器刚输出的过去样本中来提取量化阶信息。由于后向自适应能在发收两端自动生成量化阶,所以它不需要传送边信息。前向自适应和后向自适应APCM的基本概念。图中的s(k)是发送端编码器的输入信号,sr(k)是接收端译码器输出的信号。


(a) 前向自适应
(b) 后向自适应
图 APCM方块图
差分脉冲编码调制(DPCM)的概念
差分脉冲编码调制DPCM(differential pulse code modulation)是利用样本与样本之间存在的信息冗余度来进行编码的一种数据压缩技术。
差分脉冲编码调制的思想是,根据过去的样本去估算(estimate)下一个样本信号的幅度大小,这个值称为预测值,然后对实际信号值与预测值之差进行量化编码,从而就减少了表示每个样本信号的位数。它与脉冲编码调制(PCM)不同的是,PCM是直接对采样信号进行量化编码,而DPCM是对实际信号值与预测值之差进行量化编码,存储或者传送的是差值而不是幅度绝对值,这就降低了传送或存储的数据量。此外,它还能适应大范围变化的输入信号。
差分脉冲编码调制的核心算法,即Yn-Yn-1。图中,差分信号d(k)是离散输入信号s(k)和预测器输出的估算值se(k-1)之差。注意,se(k-1)是对s(k)的预测值,而不是过去样本的实际值。DPCM系统实际上就是对这个差值d(k)进行量化编码,用来补偿过去编码中产生的量化误差。DPCM系统是一个负反馈系统,采用这种结构可以避免量化误差的积累。重构信号se(k)是由逆量化器产生的量化差分信号dq(k),与对过去样本信号的估算值se(k-1)求和得到。它们的和,即sr(k)作为预测器确定下一个信号估算值的输入信号。由于在发送端和接收端都使用相同的逆量化器和预测器,所以接收端的重构信号s(k)可从传送信号I(k)获得。
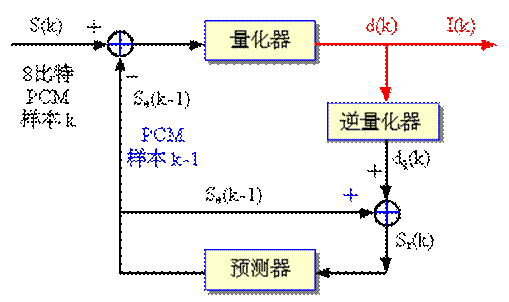
图 DPCM方块图
3 自适应差分脉冲编码调制(ADPCM)
ADPCM(adaptive difference pulse code modulation)综合了APCM的自适应特性和DPCM系统的差分特性,是一种性能比较好的波形编码。它的核心想法是:①利用自适应的思想改变量化阶的大小,即使用小的量化阶(step-size)去编码小的差值,使用大的量化阶去编码大的差值,②使用过去的样本值估算下一个输入样本的预测值,使实际样本值和预测值之间的差值总是最小。
编码简化框图如图示。
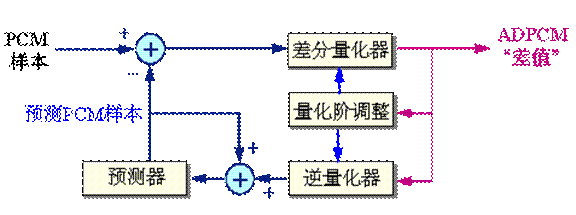
图 ADPCM方块图
接收端的译码器使用与发送端相同的算法,利用传送来的信号来确定量化器和逆量化器中的量化阶大小,并且用它来预测下一个接收信号的预测值。
G.721 ADPCM编译码器
ADPCM是利用样本与样本之间的高度相关性和量化阶自适应来压缩数据的一种波形编码技术,CCITT为此制定了G.721推荐标准,这个标准叫做32 kb/s自适应差分脉冲编码调制——32 kb/s Adaptive Differential Pulse Code Modulation。
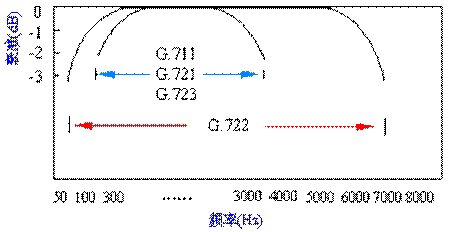
G.722标准:
描述音频信号带宽为7 kHz、数据率为64 kb/s的编译码原理、算法和计算细节的。G.722的音频信号的质量要明显高于G.711的质量,其主要目标是保持64 kb/s的数据率。G.722标准把音频信号采样频率由8 kHz提高到16 kHz,是G.711 PCM采样率的2倍,因而要被编码的信号频率由原来的3.4 kHz扩展到7 kHz,这使得音频信号的质量有很大改善。对话音信号质量来说,提高采样率并无多大改善,但对音乐一类信号来说,其质量却有很大提高。
对窄带话音和宽带音频信道作了比较。G.722编码标准在音频信号的低频端把截止频率扩展到50 Hz,其目的是为进一步改善音频信号的自然度。
这个标准把话音信号的质量由电话质量提高到AM无线电广播质量,而其数据传输率仍保持为64 kb/s。
G.722 SB-ADPCM 编译码器
子带编码(SBC)
子带编码(subband coding,SBC)的基本思想是:使用一组带通滤波器(band-pass filter,BPF)把输入音频信号的频带分成若干个连续的频段,每个频段称为子带。对每个子带中的音频信号采用单独的编码方案去编码。在信道上传送时,将每个子带的代码复合起来。在接收端译码时,将每个子带的代码单独译码,然后把它们组合起来,还原成原来的音频信号。子带编码的方块图如图所示,图中的编码/译码器,可以采用ADPCM,APCM,PCM等。
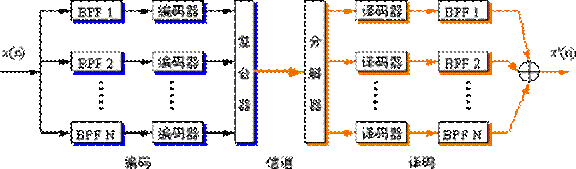
采用对每个子带分别编码的好处有二个。第一,对每个子带信号分别进行自适应控制,量化阶(quantization step)的大小可以按照每个子带的能量电平加以调节。具有较高能量电平的子带用大的量化阶去量化,以减少总的量化噪声。第二,可根据每个子带信号在感觉上的重要性,对每个子带分配不同的位数,用来表示每个样本值。例如,在低频子带中,为了保护音调和共振峰的结构,就要求用较小的量化阶、较多的量化级数,即分配较多的位数来表示样本值。而话音中的摩擦音和类似噪声的声音,通常出现在高频子带中,对它分配较少的位数。
由于分割频带所用的滤波器不是理想的滤波器,经过分带、编码、译码后合成的输出音频信号会有混迭效应。据有关资料的分析,采用正交镜象滤波器(quandrature mirror filter,QMF)来划分频带,混迭效应在最后合成时可以抵消。
图中表示用QMF把全带宽音频信号分割成两个等带宽子带的情况。hH(n)和hL(n)分别表示高通滤波器和低通滤波器,它们组成一对正交镜象滤波器。这两个滤波器也叫做分析滤波器。

(a) QMF分割频道方框图
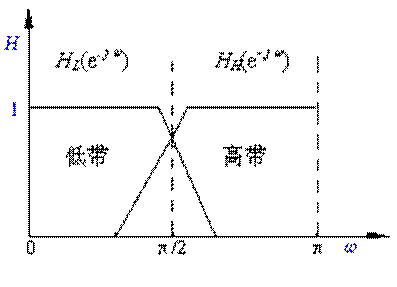
(b) QMF幅频特性简化图
图 采用QMF的子带编译码简化框图
子带-自适应差分脉冲编码调制(SB-ADPCM)
采样率为8 kHz、8位/样本、数据率为64 kb/s的G.711标准是CCITT为话音信号频率为300~3400 Hz制定的编译码标准,这属于窄带音频信号编码。现代的话音编码技术已经可以减少数据率,而又不致于显著降低音质。CCITT推荐的8 kHz采样率、4位/样本、32 kb/s的G.721标准,以及G.721的扩充标准G.723,都说明了话音压缩编码技术的进展。
在端对端(end-to-end)的数字连接应用中,加到电话网上的回音(echo)音源并不十分强。然而,当把现存窄带通信链路和宽带会议系统相互连接时,这种连接就可能引入比较强的回音源。如果宽带信号端对端的延迟不加限制,回音控制就可能变得很困难。为了简化回音控制,G.722编译码器引入的延迟时间限制在4 ms以内。
在某些应用场合中,也许希望从64 kb/s信道中让出一部分信道用来传送其它的数据。因此,G.722定了三种音频信号传送方式,如表所示。北美洲的信息限制音频信号速率为56 kb/s,因此有8 kb/s的数据率用来传送附加数据。
| 方式 | 7 kHz音频信号编码位速率 |
附加数据信道位速度 |
|---|---|---|
1 |
64 kb/s |
0 kb/s |
2 |
56 kb/s |
8 kb/s |
3 |
48 kb/s |
16 kb/s |
表 运行方式
低频带宽略大于常规的电话话音带宽。对高子带分配2位表示每个样本值,而低子带分配6位。因为64kb/s的G.722标准主要还是针对宽带话音,其次才是音乐。
G.723
在此基础上还制定了G.721的扩充推荐标准,即G.723 —— Extension of Recommendation G.721 Adaptive Differential Pulse Code Modulation to 24 and 40 kb/s for Digital Circuit Multiplication Equipment Application,使用该标准的编码器的数据率可降低到40 kb/s和24 kb/s。
G.728
建议的技术基础是美国AT&T公司贝尔实验室提出的LD-CELP(低延时-码激励线性预测)算法。该算法考虑了听觉特性,其特点是:
1. 以块为单位的后向自适应高阶预测;
2. 后向自适应型增益量化;
3. 适量为单位的激励信号量化。
G.729
和G.723.1一样,都是ITU(国际电信联盟:Iternational Telecommunication Union)所制定的最新且码率最低的两种语音压缩国际标准,算法也比较复杂。 G.729语音压缩编码系统的原理与基本CELP算法是一致的。为了提高合成语音质量,采取了一些措施,具体的算法比较复杂。
CCITT推荐的G.721 ADPCM标准是一个代码转换系统。它使用ADPCM转换技术,实现64 kb/s A律或μ律PCM速率和32 kb/s速率之间的相互转换。G.721 ADPCM的简化框图如图所示。
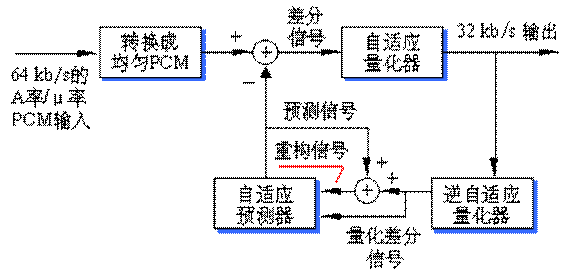
(a) ADPCM编码器
图 G.721 ADPCM简化框图
在图3-16(a)所示的编码器中,A律或μ律PCM输入信号转换成均匀的PCM。差分信号等于均匀的PCM输入信号与预测信号之差。“自适应量化器”用4位二进制数表示差分信号,但只用其中的15个数(即15个量级)来表示差分信号,这是为防止出现全“0”信号。“逆自适应量化器”从这4位相同的代码中产生量化差分信号。预测信号和这个量化差分信号相加产生重构信号。“自适应预测器”根据重构信号和量化差分信号产生输入信号的预测信号,这样就构成了一个负反馈回路。
G.721 ADPCM编译码器的输入信号是G.711 PCM代码,采样率是8 kHz,每个代码用8位表示,因此它的数据率为64 kb/s。而G.721 ADPCM的输出代码是“自适应量化器”的输出,该输出是用4位表示的差分信号,它的采样率仍然是8 kHz,它的数据率为32 kb/s,这样就获得了2∶1的数据压缩。
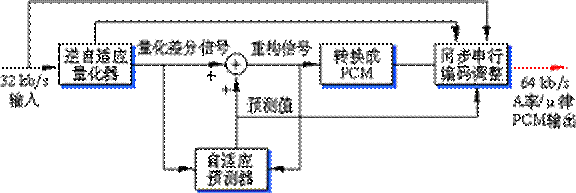
(b) ADPCM译码器
在图3-16(b)所示的译码器中,译码器的部分结构与编码器负反馈回路部分相同。此外,还包含有均匀PCM到A律或μ律PCM的转换部分,以及同步编码调整(synchronous coding adjustment)部分。设置同步(串行)编码调整的目的是为防止在同步串行编码期间出现的累积信号失真。
5.6 MPEG Audio编码技术
5.6.1 听觉系统的感知特性
在MPEG Audio压缩编码算法中的三个特性:响度、音高和掩蔽效应。
声音的强弱也叫做响度。在心理上,主观感觉的声音强弱使用响度级“方(phon)”或者“宋(sone)”来度量。在物理上,声音的响度使用客观测量单位来度量,即dyn/cm2(达因/平方厘米)(声压)或W/cm2(瓦特/平方厘米)(声强)。这两种感知声音强弱的计量单位是完全不同的两种概念,但是它们之间又有一定的联系。
当声音弱到人的耳朵刚刚可以听见时,我们称此时的声音强度为“听阈”。例如,1 kHz纯音的声强达到10-16w/cm2(定义成零dB声强级)时,人耳刚能听到,此时的主观响度级定为零方。有关实验表明,听阈是随频率变化的。测出的“听阈—频率”曲线如图4-7所示。图中最靠下面的一根曲线是在安静环境中,能被人耳听到的纯音的最小值,叫做“零方等响度级”曲线,也称“绝对听阈”曲线。
另一种极端的情况是声音强到使人耳感到疼痛。有实验表明,如果频率为1 kHz的纯音的声强级达到120 dB左右时,人的耳朵就感到疼痛,这个阈值称为“痛阈”。对不同的频率进行测量,可以得到“痛阈—频率”曲线,如图4-7中最靠上面所示的一根曲线。这条曲线也就是120方等响度级曲线。
在“听阈—频率”曲线和“痛阈—频率”曲线之间的区域就是人耳的听觉范围。这个范围内的等响度级曲线也是用同样的方法测量出来的。由图4-7可以看出,1 kHz的10 dB的声音和200 Hz的30 dB的声音,在人耳听起来具有相同的响度。
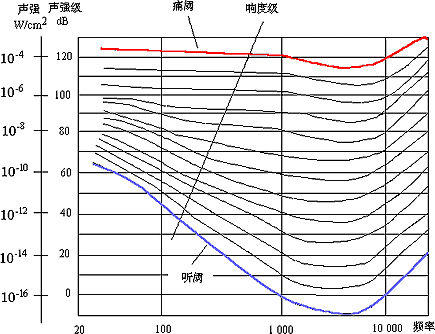
图4-7 “听阈—频率”曲线
图4-7表明了人耳对不同频率的敏感程度差别很大,其中对2 kHz~4 kHz范围的信号最为敏感,幅度很低的信号都能被人耳听到。而在低频区和高频区,能被人耳听到的信号幅度要高得多。
音高
客观上用频率来表示声音的音高,其单位是Hz。而主观感觉的音高单位则是“美(Mel)”,主观音高与客观音高的关系是
![]() (4.1)
(4.1)
其中f的单位为Hz,这也是两个既不相同又有联系的单位。
人耳对响度的感觉有一个范围,即从听阈到痛阈。同样,人耳对频率的感觉也有一个范围。人耳可以听到的最低频率约20 Hz,最高频率约18000 Hz。正如测量响度时是以1 kHz纯音为基准一样,在测量音高时则以40dB声强为基准,并且同样由主观感觉来确定。
测量主观音高时,让实验者听两个声强级为40 dB的纯音,固定其中一个纯音的频率,调节另一个纯音的频率,直到他感到后者的音高为前者的两倍,就标定这两个声音的音高差为两倍。实验表明,音高与频率之间也不是线性关系。测出的“音高—频率”曲线如图4-8所示。
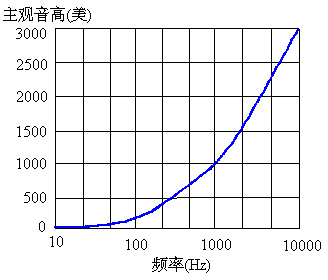
图4-8 “音高—频率”曲线
掩蔽效应
一种频率的声音阻碍听觉系统感受另一种频率的声音的现象称为掩蔽效应。前者称为掩蔽声音(masking tone),后者称为被掩蔽声音(masked tone)。掩蔽可分成时域掩蔽和频域掩蔽。掩蔽效应十分重要,它是心理声学模型的基础。
1. 时域掩蔽
在时间上,相邻的声音之间存在着掩蔽现象,并且称为时域掩蔽。时域掩蔽又分为超前掩蔽(pre-masking)和滞后掩蔽(post-masking),如图4-9所示。产生时域掩蔽的主要原因是人的大脑处理信息需要花费一定的时间。一般来说,超前掩蔽很短,只有大约5~20 ms,而滞后掩蔽可以持续50~200 ms。这个区别也是很容易理解的。
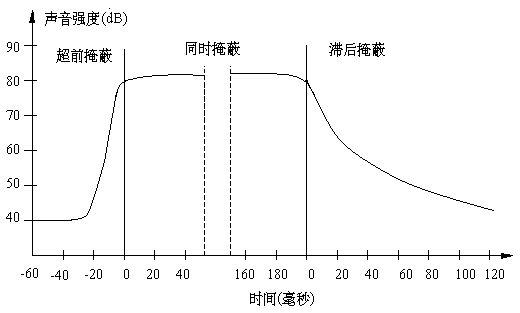
图4-9时域掩蔽
2. 频域掩蔽
一个强纯音会掩蔽在其附近同时发声的弱纯音,这种特性称为频域掩蔽,也称同时掩蔽(simultaneous masking), 如图4-10所示。从图4-10可以看到,声音频率在300 Hz附近、声强约为60 dB的声音掩蔽了声音频率在150 Hz附近、声强约为40 db的声音。又如,一个声强为60 dB、频率为1000 Hz的纯音,另外还有一个1100 Hz的纯音,前者比后者高18 dB,这样的话,我们的耳朵就只能听到那个1000 Hz的强音。如果有一个1000 Hz的纯音和一个声强比它低18 dB的2000 Hz的纯音,那么我们的耳朵将会同时听到这两个声音。要想让2000 Hz的纯音也听不到,则需要把它降到比1000 Hz的纯音低45 dB。一般来说,弱纯音离强纯音越近就越容易被掩蔽。
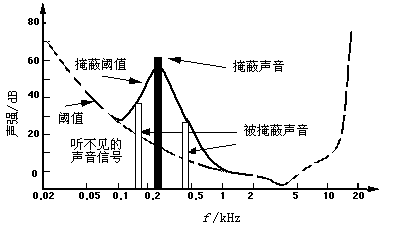
图4-10 声强为60 dB、频率为1000 Hz纯音的掩蔽效应
在图4-11中的一组曲线分别表示频率为250 Hz,1 kHz和4 kHz纯音的掩蔽效应,它们的声强均为60 dB。从图14-04中可以看到:①在250 Hz,1 kHz和4 kHz纯音附近,对其他纯音的掩蔽效果最明显,②低频纯音可以有效地掩蔽高频纯音,但高频纯音对低频纯音的掩蔽作用则不明显。
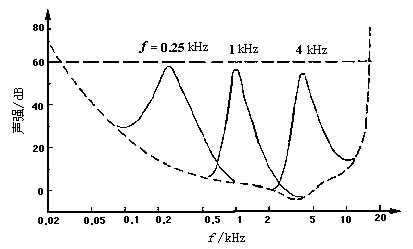
图4-11 不同纯音的掩蔽效应曲线
由于声音频率与掩蔽曲线不是线性关系,为了达到从感知上统一二者的目的,度量声音频率,引入了“临界频带(critical band)”的概念。通常认为,在20 Hz到16 kHz范围内有24个临界频带,如表4-1所示。临界频带的单位叫Bark(巴克),
1 Bark = 一个临界频带的宽度
f(频率)< 500 Hz的情况下, 1 Bark≈f/100
f(频率) > 500 Hz的情况下, 1Bark≈9 + 4log(f/1000)
表4-1 临界频带
临界 频带 |
频率 (Hz) |
临界 |
频率 (Hz) |
||||
低端 |
高端 |
宽度 |
低端 |
高端 |
宽度 |
||
0 |
0 |
100 |
100 |
13 |
2000 |
2320 |
320 |
1 |
100 |
200 |
100 |
14 |
2320 |
2700 |
380 |
2 |
200 |
300 |
100 |
15 |
2700 |
3150 |
450 |
3 |
300 |
400 |
100 |
16 |
3150 |
3700 |
550 |
4 |
400 |
510 |
110 |
17 |
3700 |
4400 |
700 |
5 |
510 |
630 |
120 |
18 |
4400 |
5300 |
900 |
6 |
630 |
770 |
140 |
19 |
5300 |
6400 |
1100 |
7 |
770 |
920 |
150 |
20 |
6400 |
7700 |
1300 |
8 |
920 |
1080 |
160 |
21 |
7700 |
9500 |
1800 |
9 |
1080 |
1270 |
190 |
22 |
9500 |
12000 |
2500 |
10 |
1270 |
1480 |
210 |
23 |
12000 |
15500 |
3500 |
11 |
1480 |
1720 |
240 |
24 |
15500 |
22050 |
6550 |
12 |
1720 |
2000 |
280 |
|
|
|
|
5.6.2 MPEG Audio与感知特性
MPEG Audio(MPEG声音)标准在本书中是指MPEG-1 Audio、MPEG-2 Audio和MPEG-2 AAC,它们处理的是10 Hz~20000 Hz范围里的声音数据,数据压缩的主要依据是人耳朵的听觉特性,是使用“心理声学模型(psychoacoustic model)”来达到压缩声音数据的目的。
心理声学模型中的一个概念是听觉掩饰特性,意思是听觉阈值电平是自适应的,即听觉阈值电平会随听到的不同频率的声音而发生变化。例如,同时有两种频率的声音存在,一种是1000 Hz的声音,另一种是1100 Hz的声音,但它的强度比前者低18分贝,在这种情况下,1100 Hz的声音就听不到。也许你有这样的体验,在一安静房间里的普通谈话可以听得很清楚,但在播放摇滚乐的环境下同样的普通谈话就听不清楚了。声音压缩算法也同样可以确立这种特性的模型来取消更多的冗余数据。
另外,听觉阈值电平在心理声学模型中也是一个基本的概念。由于低于这个电平的声音信号听不到,因此就可以把这部分信号去掉,从而消除了部分冗余。听觉阈值的大小随声音频率的改变而改变,各个人的听觉阈值也不同。大多数人的听觉系统对2 kHz~5 kHz之间的声音最敏感。一个人是否能听到声音取决于声音的频率,以及声音的幅度是否高于这种频率下的听觉阈值。
MPEG Audio采纳两种感知编码,一种叫做感知子带编码(perceptual subband coding ),另一种是由杜比实验室(Dolby Laboratories)开发的Dolby AC-3 (Audio Code number 3)编码,简称AC-3。它们都利用人的听觉系统的特性来压缩数据,只是压缩数据的算法不同。
感知子带编码又叫做子带编码,我们前面已经介绍过了。其简化算法框图如图4-12所示。输入信号通过“滤波器组”进行滤波之后被分割成许多子带,每个子带信号对应一个“编码器”,然后根据心理声学模型对每个子带信号进行量化和编码,输出量化信息和经过编码的子带样本,最后通过“多路复合器”把每个子带的编码输出按照传输或者存储格式的要求复合成数据位流(bit stream)。解码过程与编码过程相反。
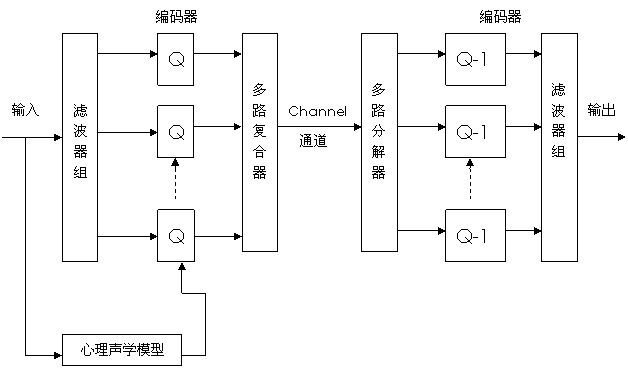
图4-12 MPEG Audio压缩算法框图
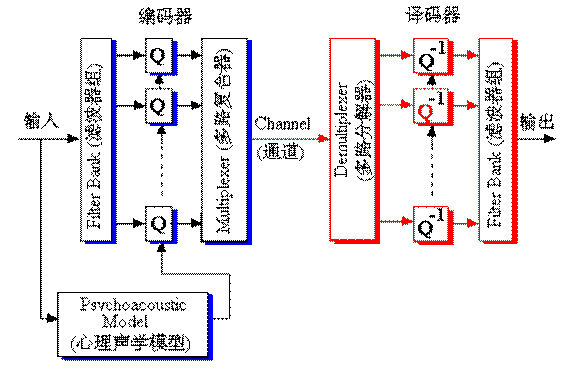
图 MPEG Audio压缩算法框图
Dolby AC-3是MPEG-2采纳的声音编码技术。Dolby AC-3是一种多通道(multichannel)音乐信号压缩技术,它可支持5个3 Hz~20 000 Hz频率范围的通道。AC-3压缩编码算法的简化框图如图所示。它的输入是未被压缩的PCM样本,而PCM样本的采样频率必须是32, 44.1或者48 kHz,样本精度可多到20位。
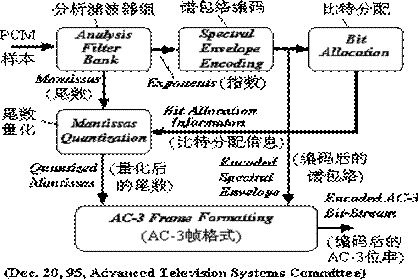
图 Dolby AC-3压缩编码算法框图
各部分的功能如下:
分析滤波器组(analysis filter bank):它的功能是把用PCM时间样本表示的声音信号变换成用频率系数块(frequencies coefficients block)表示的声音信号。输入信号从时间域变换到频率域是用时间窗(time window)乘由512个时间样本组成的交叠块(overlapping block)来实现的。在频率域中用因子2对每个系数块进行抽取,因此每个系数块就包含256个频率系数。单个频率系数用浮点二进制的指数(exponent)和尾数(mantissa)表示。
频谱包络(spectral envelope encoding):它的功能是对“分析滤波器组”输出的指数进行编码。指数代表粗糙的信号频谱,因此称为(频)“谱包络编码。”
位分配(bit allocation):它的功能是使用“谱包络编码”输出的信息确定尾数编码所需要的位数。
尾数量化(mantissa quantization):它的功能是按照“位分配”输出的位分配信息对尾数进行量化。
AC-3帧格式(AC-3 frame formatting):它的功能是把“尾数量化”输出的量化尾数和“谱包络编码”输出的频谱包络组成AC-3帧。一帧由6个声音块(1356个声音样本)组成。“AC-3帧格式”输出的是AC-3编码位流,它的位速率为32~640 kbps。
5.6.3 MPEG-1 Audio
1 声音编码
声音的数据量由两方面决定:采样频率和样本精度。对单声道信号而言,每秒钟的数据量(位数)=采样频率×样本精度。要减小数据量,就需要降低采样频率或者降低样本精度。由于人耳可听到的声音的频率范围大约是20 Hz~20 kHz,根据奈奎斯特理论,要想不失真地重构信号,采样频率不能低于40 kHz。又考虑到实际中使用的滤波器都不可能是理想滤波器,以及各国所用的交流电源的频率不同,为保证声音频带的宽度,所以采样频率一般不能低于44.1 kHz。在MPEG-1 Audio中,编码器的输入信号的样本精度通常是16位,因此声音的数据压缩就必须从降低样本精度这个角度出发,即减少每位样本所需要的位数。
MPEG-1 Audio的编码对象是20~20000Hz的宽带声音,因此它采用了子带编码。MPEG声音数据压缩的基础是量化。虽然量化会带来失真,但MPEG标准要求量化失真对于人耳来说是感觉不到的。在MPEG标准的制定过程中,MPEG-Audio委员会作了大量的主观测试实验。实验表明,采样频率为48 kHz、样本精度为16位的立体声音数据压缩到256 kb/s时,即在6:1的压缩率下,即使是专业测试员也很难分辨出是原始声音还是编码压缩后的声音。
2 声音的性能
MPEG声音标准是MPEG标准的一部分,但它也完全可以独立应用。MPEG-1 Audio(ISO/IEC 11172-3)压缩算法是世界上第一个高保真声音数据压缩国际标准,并且得到了极其广泛的应用。MPEG-1声音标准的主要性能如下:
1)如图4-13所示,MPEG编码器的输入信号为线性PCM信号,采样率为32, 44.1或48 kHz,输出为32 kb/s~384 kb/s。

图4-13 MPEG编码器的输入/输出
2) MPEG声音标准提供三个独立的压缩层次:层1(Layer 1)、层2(Layer 2)和层3(Layer 3),用户可以根据复杂性和声音质量在层次之间进行选择。
层1的编码器比较的简单,编码器的输出数据率为384 kb/s,主要用于小型数字盒式磁带(digital compact cassette,DCC)。层2的编码器的复杂程度属中等,编码器的输出数据率为256 kb/s~192 kb/s,其应用包括数字广播声音(digital broadcast audio,DBA)、数字音乐、CD-I(compact disc-interactive)和VCD(video compact disc)等。层3的编码器最为复杂,编码器的输出数据率为64 kb/s,主要应用于ISDN上的声音传输。
在尽可能保持CD音质为前提的条件下,MPEG声音标准一般所能达到的压缩率如表4-2所示,从编码器的输入到输出的延迟时间如表4-3所示。
表4-2 MPEG声音的压缩率
| 层次 |
算法 |
压缩率 |
立体声信号所对应的位率( kb/s) |
|---|---|---|---|
1 |
MUSICAM* |
4:1 |
384 |
2 |
MUSICAM* |
6:1 ~ 8:1 |
256 ~ 192 |
3 |
ASPEC** |
10:1 ~ 12:1 |
128 ~ 112 |
* MUSICAM(Masking pattern adapted Universal Subband Integrated Coding And Multiplexing) 自适应声音掩蔽特性的通用子带综合编码和复合技术
** ASPEC(Adaptive Spectral Perceptual Entropy Coding of high quality musical signal) 高质量音乐信号自适应谱感知熵编码(技术)
表4-3 MPEG编码解码器的延迟时间
| 延迟时间 | 理论最小值( ms) |
实际实现中的一般值( ms) |
|---|---|---|
层1(Layer 1) |
19 |
< 50 |
层2(Layer 2) |
35 |
100 |
层3(Layer 3) |
59 |
150 |
3) 可预先定义压缩后的数据率,如表4-4所示。另外,MPEG声音标准也支持用户预定义的数据率。
表4-4 MPEG层3在各种数据率下的性能:
音质要求 |
声音带宽(kHz) |
方式 |
数据率( kb/s) |
压缩比 |
|---|---|---|---|---|
电话 |
2.5 |
单声道 |
8 |
96 :1 |
优于短波 |
5.5 |
单声道 |
16 |
48 :1 |
优于调幅广播 |
7.5 |
单声道 |
32 |
24 :1 |
类似于调频广播 |
11 |
立体声 |
56 ~ 64 |
26 ~ 24 :1 |
接近CD |
15 |
立体声 |
96 |
16 :1 |
CD |
> 15 |
立体声 |
112 ~ 128 |
12 ~ 10 :1 |
4) 编码后的数据流支持循环冗余校验CRC(cyclic redundancy check)。
5) MPEG声音标准还支持在数据流中添加附加信息。
MPEG-1声音编码器的结构如图4-14所示。输入声音信号经过一个“时间-频率多相滤波器组”变换到频域里的多个子带中。输入声音信号同时经过“心理声学模型(计算掩蔽特性)”,该模型计算以频率为自变量的噪声掩蔽阈值(masking threshold),查看输入信号和子带中的信号以确定每个子带里的信号能量与掩蔽阈值的比率。“量化和编码”部分用信掩比(signal-to-mask ratio,SMR)来决定分配给子带信号的量化位数,使量化噪声低于掩蔽阈值。最后通过“数据流帧包装”将量化的子带样本和其他数据按照规定的称为“帧(frame)”的格式组装成位数据流。
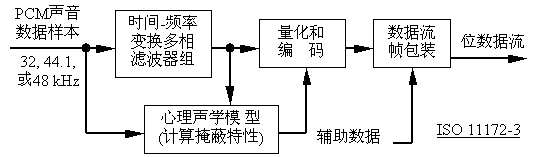
图4-14 MPEG声音编码器结构图
信掩比(SMR)是指最大的信号功率与全局掩蔽阈值之比。图4-15表示某个临界频带中的掩蔽阈值和信掩比,人们把“掩蔽音”电平和“掩蔽阈值”之间的距离叫做信掩比。在图4-15所示的临界频带中,“掩蔽阈值”曲线之下的声音可被“掩蔽音”掩蔽掉。此外,在图4-15中还表示了信噪比(signal noise ratio,SNR)和噪掩比(noise-to-mask ratio,NMR)。
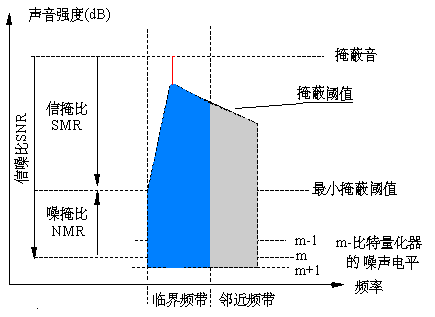
图4-15 掩蔽阈值和SMR
图4-16是MPEG-1声音解码器的结构图。解码器对位数据流进行解码,恢复被量化的子带样本值以重建声音信号。由于解码器无需心理声学模型,只需拆包、重构子带样本和把它们变换回声音信号,因此解码器就比编码器简单得多。
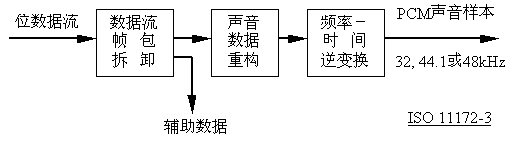
图4-16 MPEG声音解码器结构图
3 子带编码
MPEG-1使用子带编码来达到既压缩声音数据又尽可能保留声音原有质量的目的。SBC的基本想法就是在编码过程中保留信号的带宽而扔掉被掩蔽的信号,其结果是编码之后还原的声音,也就是解码或者叫做重构的声音信号与编码之前的声音信号不相同,但人的听觉系统很难感觉到它们之间的差别。这也就是说,对听觉系统来说这种压缩是“无损压缩”。
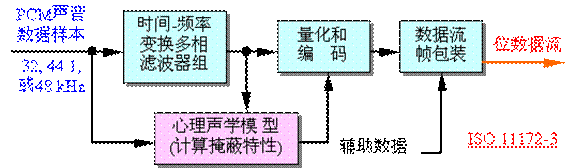
图 MPEG声音编码器结构图
图是MPEG-1声音解码器的结构图。解码器对位数据流进行解码,恢复被量化的子带样本值以重建声音信号。由于解码器无需心理声学模型,只需拆包、重构子带样本和把它们变换回声音信号,因此解码器就比编码器简单得多。

图 MPEG声音解码器结构图
4 多相滤波器组
在MPEG-1中,多相滤波器组是MPEG声音压缩的关键部分部件之一,它把输入信号变换到32个频域子带中去。子带的划分方法有两种,一种是线性划分,另一种是非线性划分。如果把声音频带划分成带宽相等的子带,这种划分就不能精确地反映人耳的听觉特性,因为人耳的听觉特性是以“临界频带”来划分的,在一个临界频带之内,很多心理声学特性都是一样的。在低频区域,多相滤波器组的一个子带覆盖好几个临界频带。在这种情况下,某个子带中量化器的位分配就不能根据每个临界频带的掩蔽阈值进行分配,而要以其中最低的掩蔽阈值为准。 '
5 编码层
如前面介绍的,MPEG声音压缩定义了3个层次,它们的基本模型是相同的。层1是最基础的,层2和层3都在层1的基础上有更高的压缩比,但需要更复杂的编码解码器。MPEG声音的每一个层都自含SBC编码器,其中包含如图4-14所示的“时间-频率多相滤波器组”、“心理声学模型(计算掩蔽特性)”、“量化和编码”和“数据流帧包装”,而高层SBC可使用低层SBC编码的声音数据。
MPEG的声音数据分成帧(frame),层1每帧包含384个样本的数据,每帧由32个子带分别输出的12个样本组成。层2和层3每帧为1152个样本,如图4-17所示。
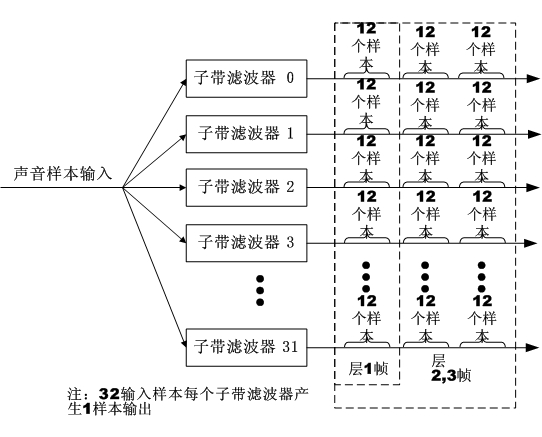
图4-17 层1、2和层3的子带样本
MPEG编码器的输入以12个样本为一组,每组样本经过时间-频率变换之后进行一次位分配并记录一个比例因子(scale factor)。位分配信息告诉解码器每个样本由几位表示,比例因子用6位表示,解码器使用这个6位的比例因子乘逆量化器的每个输出样本值,以恢复被量化的子带值。比例因子的作用是充分利用量化器的量化范围,通过位分配和比例因子相配合,可以表示动态范围超过120 dB的样本。
下面我们来分别介绍每个层次的原理结构。
1)层1
层1的子带是频带相等的子带,它的心理声学模型仅使用频域掩蔽特性。层1和层2的比较详细的框图如图4-18所示。在图4-18中,“分析滤波器组”相当于图4-14“时间-频率多相滤波器组”,它使用与离散余弦变换(discrete cosine transform,DCT)类似的算法对输入信号进行变换。与此同时,使用与“分析滤波器组”并行的快速傅立叶变换(fast Fourier transform,FFT)对输入信号进行频谱分析,并根据信号的频率、强度和音调,计算出掩蔽阈值,然后组合每个子带的单个掩蔽阈值以形成全局的掩蔽阈值。使用这个阈值与子带中的最大信号进行比较,从而产生信掩比(SMR)。
在图4-18中,“比例和量化器”和“动态比特和比例因子分配器和编码器”合在一起相当于图4-14中的“量化和编码器”。“比例和量化器”首先检查每个子带的样本,找出这些样本中的最大的绝对值,然后量化成6位,这个位数称为比例因子(scale factor)。“动态比特和比例因子分配器和编码器”根据SMR确定每个子带的位分配(bit allocation),子带样本按照位分配进行量化和编码。对被高度掩蔽的子带自然就不需要对它进行编码。

图4-18 ISO/MPEG audio层1和层2编码器和解码器的结构
在图4-18中,MUX(多路复合器)相当于图4-14中的“数据流帧包装”,它按规定的帧格式对声音样本和编码信息(包括比特分配合比例因子等)进行包装。层1的帧结构如图4-19所示。每帧都包含:①用于同步和记录该帧信息的同步头,长度为32位,它的结构如图4-20所示,②用于检查是否有错误的循环冗余码(cyclic redundancy code,CRC),长度为16位,③用于描述位分配的位分配域,长度为4位,④比例因子域,长度为6位,⑤子带样本域,⑥有可能添加的附加数据域,长度未规定。

图4-19 层1的帧结构
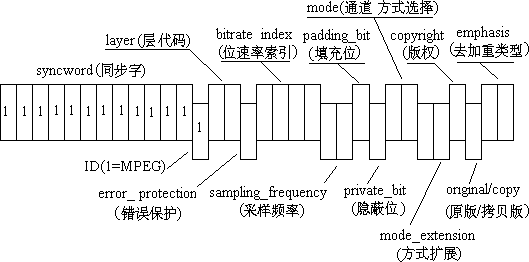
图4-20 MPEG声音位流同步头的格式
2) 层2
层1是对一个子带中的一个样本组(由12个样本组成)进行编码,而层2和层3是对一个子带中的三个样本组进行编码。图4-17也表示了层2和层3的分组方法。层2对层1作了一些直观的改进,相当于3个层1的帧,每帧有1152个样本。它使用了频域掩蔽特性以及时间掩蔽特性,并且在低、中和高频段对位分配作了一些限制,对位分配、比例因子和量化样本值的编码也更紧凑。由于层2采用了上述措施,因此所需的位数减少了,这样就可以有更多的位用来表示声音数据,音质也比层1更高。
如图4-21所示,层2使用与层1相同的同步头和CRC结构,但描述位分配的位数随子带不同而变化:低频段的子带用4位,中频段的子带用3位,高频段的子带用2位。层2位流中有一个比例因子选择信息(scale factor selection information,SCFSI)域,解码器根据这个域的信息可知道是否需要以及如何共享比例因子。
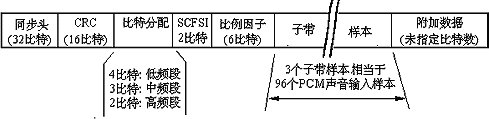
图4-21 层2位流数据格式
3) 层3
层3使用比较好的临界频带滤波器,把声音频带分成非等带宽的子带,心理声学模型除了使用频域掩蔽特性和时间掩蔽特性之外,还考虑了立体声数据的冗余,并且使用了霍夫曼(Huffman)编码器。层3编码器的详细框图如图4-22所示。
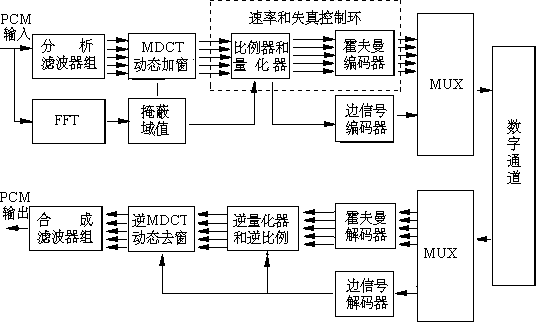
图4-22 ISO/MPEG audio层3编码器和解码器的结构
层3使用了从ASPEC(Audio Spectral Perceptual Entropy Encoding)和OCF(optimal coding in the frequency domain)导出的算法,比层1和层2都要复杂。虽然层3所用的滤波器组与层1和层2所用的滤波器组的结构相同,但是层3还使用了改进离散余弦变换(modified discrete cosine transform,MDCT),对层1和层2的滤波器组的不足作了一些补偿。MDCT把子带的输出在频域里进一步细分以达到更高的频域分辨率。而且通过对子带的进一步细分,层3编码器已经部分消除了多相滤波器组引入的混迭效应。
层3指定了两种MDCT的块长:长块的块长为18个样本,短块的块长为6个样本,相邻变换窗口之间有50%的重叠。长块对于平稳的声音信号可以得到更高的频域分辨率,而短块对跳变的声音信号可以得到更高的时域分辨率。在短块模式下,3个短块代替1个长块,而短块的大小恰好是一个长块的1/3,所以MDCT的样本数不受块长的影响。对于给定的一帧声音信号,MDCT可以全部使用长块或全部使用短块,也可以长短块混合使用。因为低频区的频域分辨率对音质有重大影响,所以在混合块长模式下,MDCT对最低频的2个子带使用长块,而对其余的30个子带使用短块。这样,既能保证低频区的频域分辨率,又不会牺牲高频区的时域分辨率。长块和短块之间的切换有一个过程,一般用一个带特殊长转短或短转长数据窗口的长块来完成这个长短块之间的切换。
除了使用MDCT外,层3还采用了其他许多改进措施来提高压缩比而不降低音质。虽然层3引入了许多复杂的概念,但是它的计算量并没有比层2增加很多。增加的主要是编码器的复杂度和解码器所需要的存储容量。
5.6.4 MPEG-2 Audio
MPEG-2 Audio(ISO/IEC 13818-3)和MPEG-1 Audio(ISO/IEC 1117-3)标准都使用相同种类的编译码器,层1, 2和3的结构也相同。MPEG-2声音标准与MPEG-1标准相比,MPEG-2做了如下扩充:①增加了16 kHz, 22.05 kHz和24 kHz采样频率,②扩展了编码器的输出速率范围,由32~384 kb/s扩展到8~640 kb/s,③增加了声道数,支持5.1声道和7.1声道的环绕声。此外MPEG-2还支持Linear PCM(线性PCM)和Dolby AC-3(Audio Code Number 3)编码。它们的差别如表4-5所示。
表4-5 MPEG-1和-2的声音数据规格
参数名称 |
Linear PCM |
Dolby AC-3 |
MPEG-2 Audio |
MPEG-1 Audio |
采用频率 |
48/96 kHz |
32/44.1/48 kHz |
16/22.05/24/32/44.1/48 kHz |
32/44.1/48 kHz |
样本精度(每个样本的位数) |
16/20/24 |
压缩(16 bits) |
压缩(16 bits) |
16 |
最大数据传输率 |
6.144 Mb/s |
448 kb/s |
8~640 kb/s |
32~448 kb/s |
最大声道数 |
8 |
5.1 |
5.1/7.1 |
2 |
MPEG-2 Audio的“5.1环绕声”也称为“3/2-立体声加LFE”,其中的“.1”就是指LFE声道。它的含义是播音现场的前面可有3个喇叭声道(左、中、右),后面可有2个环绕声喇叭声道,LFE(low frequency effects)是低频音效的加强声道,7.1声道环绕立体声与5.1类似。只是比5.1声道立体环绕声多了中左、中右两个喇叭声道。
MPEG-2声音标准的第3部分(Part 3)是MPEG-1声音标准的扩展,扩展部分就是多声道扩展(multichannel extension),如图4-23所示。这个标准称为MPEG-2后向兼容多声道声音编码(MPEG-2 backwards compatible multichannel audio coding)标准,简称为MPEG-2 BC。
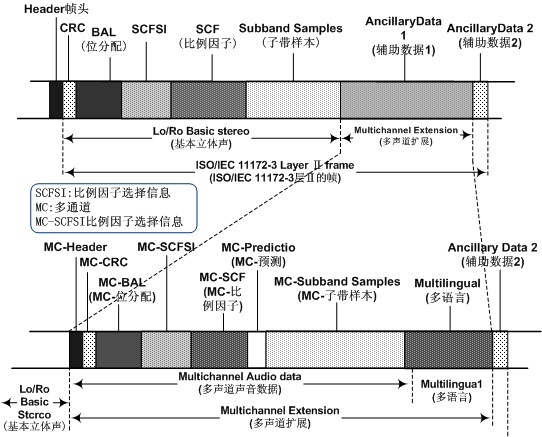
图4-23 MPEG-2 Audio的数据块(引自 ISO/IEC 13818-3)
5.6.5 MPEG-2 AAC
MPEG-2 AAC是什么
MPEG-2 AAC是MPEG-2标准中的一种非常灵活的声音感知编码标准。就像所有感知编码一样,MPEG-2 AAC主要使用听觉系统的掩蔽特性来减少声音的数据量,它可以通过把量化噪声分散到各个子带中从而用全局信号把噪声掩蔽掉。
AAC编码器的音源可以是单声道的、立体声的和多声道的声音,支持的采样频率可从8 kHz到96 kHz。AAC标准可支持48个主声道、16个低频音效加强通道LFE (low frequency effects)、16个配音声道(overdub channel)或者叫做多语言声道(multilingual channel)和16个数据流。MPEG-2 AAC在压缩比为11:1,即每个声道的数据率为(44.1×16 )/11=64 kb/s,而5个声道的总数据率为320 kb/s的情况下,很难区分还原后的声音与原始声音之间的差别。与MPEG的层2相比,MPEG-2 AAC的压缩率可提高1倍,而且质量更高,与MPEG的层3相比,在质量相同的条件下数据率是它的70%。
MPEG-2 AAC的配置
开发MPEG-2 AAC标准采用的方法与开发MPEG Audio标准采用的方法不同。后者采用的方法是对整个系统进行标准化,而前者采用的方法是模块化的方法,把整个AAC系统分解成一系列模块,用标准化的AAC工具(advanced audio coding tools)对模块进行定义,因此在其他书籍中往往把“模块(modular)”与“工具(tool)”等同对待。
AAC定义的编码和解码的基本结构如图4-24和图4-25所示。AAC标准定义了三种配置:基本配置、低复杂性配置和可变采样率配置:
1)基本配置(Main Profile):
在这种配置中,除了“增益控制(Gain Control)”模块之外,AAC系统使用了图中所示的所有模块,在三种配置中提供最好的声音质量,而且AAC的解码器可以对低复杂性配置编码的声音数据进行解码,但对计算机的存储器和处理能力的要求方面,基本配置比低复杂性配置的要求高。
2)低复杂性配置(Low Complexity Profile):
在这种配置中,不使用预测模块和预处理模块,瞬时噪声定形(temporal noise shaping,TNS)滤波器的级数也有限,这就使声音质量比基本配置的声音质量低,但对计算机的存储器和处理能力的要求可明显减少。
3)可变采样率配置(Scalable Sampling Rate Profile):
在这种配置中,使用增益控制对信号作预处理,不使用预测模块,TNS滤波器的级数和带宽也都有限制,因此它比基本配置和低复杂性配置更简单,可用来提供可变采样频率信号。
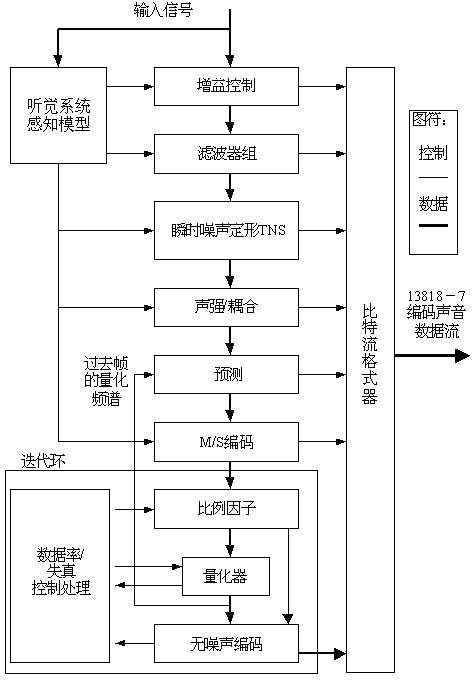
图4-24 MPEG-2 AAC编码器框图
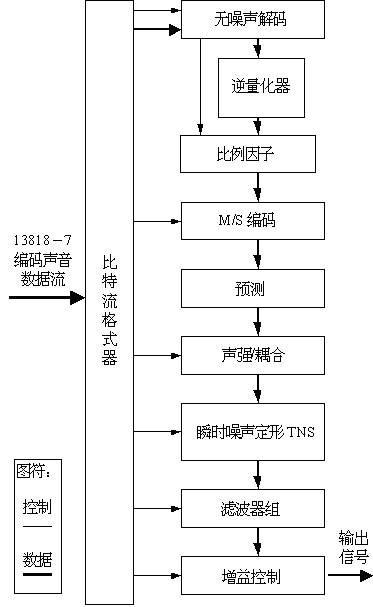
图4-25 MPEG-2 AAC解码器框图
MPEG-2 AAC的基本模块
MPEG-2 AAC编码器和解码器的框图分别示于图4-24和图4-25。现将其中的几个模块作一些说明。
1. 增益控制(Gain control)
增益控制模块用在可变采样率配置中,它由多相正交滤波器PQF(polyphase quadrature filter)、增益检测器(gain detector)和增益修正器(gain modifier)组成。这个模块把输入信号分离到4个相等带宽的频带中。在解码器中也有增益控制模块,通过忽略PQF的高子带信号获得低采样率输出信号。
2. 滤波器组(Filter Bank)
滤波器组是把输入信号从时域变换到频域的转换模块,它是MPEG-2 AAC系统的基本模块。这个模块采用了改进离散余弦变换MDCT,它是一种线性正交交迭变换,使用了一种称为时域混迭取消TDAC(time domain aliasing cancellation)技术。
MDCT使用KBD(Kaiser-Bessel derived)窗口或者使用正弦(sine)窗口,正向MDCT变换可使用下式表示:
![]()
![]() (4.2)
(4.2)
逆向MDCT变换可使用下式表示:
![]()
![]() (4.3)
(4.3)
其中,n=样本号,
N=变换块长度,
i=块号,
![]()
3. 瞬时噪声定形TNS
在感知声音编码中,TNS模块是用来控制量化噪声的瞬时形状的一种方法,解决掩蔽阈值和量化噪声的错误匹配问题。这种技术的基本想法是,在时域中的音调声信号在频域中有一个瞬时尖峰,TNS使用这种双重性来扩展已知的预测编码技术,把量化噪声置于实际的信号之下以避免错误匹配。
4. 联合立体声编码
联合立体声编码(joint stereo coding)是一种空间编码技术,其目的是为了去掉空间的冗余信息。MPEG-2 AAC系统包含两种空间编码技术:M/S编码(Mid/Side encoding)和声强/耦合(Intensity /Coupling)。M/S编码使用矩阵运算,因此把M/S编码称为矩阵立体声编码(matrixed stereo coding)。M/S编码也叫做“和-差编码(sum-difference coding)”。 声强/耦合编码探索的基本问题是声道间的不相关性(irrelevance)。
5. 预测(Prediction)
这是在话音编码系统中普遍使用的一种技术,它主要用来减少平稳(stationary)信号的冗余度。
6. 量化器(Quantizer)
使用了非均匀量化器。
7. 无噪声编码(Noiseless coding)
无噪声编码实际上就是霍夫曼编码,它对被量化的谱系数、比例因子和方向信息进行编码。
5.6.6 MPEG-4 Audio
MPEG-4 Audio标准可集成从话音到高质量的多通道声音,从自然声音到合成声音,编码方法还包括参数编码(parametric coding),码激励线性预测(code excited linear predictive,CELP)编码,时间/频率T/F(time/frequency)编码,结构化声音SA(structured audio)编码和文本-语音TTS(text-to-speech)系统的合成声音等。
1 自然声音
MPEG-4声音编码器支持数据率介于2 kb/s和64 kb/s之间的自然声音(natural audio)。为了获得高质量的声音,MPEG-4定义了三种类型的声音编码器分别用于不同类型的声音,它的一般编码方案如图4-26所示。
1. 参数编码器
使用声音参数编码技术。对于采样率为8 kHz的话音(speech),编码器的输出数据率为2~4 kb/s;对于采样频率为8 kHz或者16 kHz的声音(audio),编码器的输出数据率为4~16 kb/s。
2. CELP编码器
使用CELP(code excited linear predictive)技术。编码器的输出数据率在6~24 kb/s之间,它用于采样频率为8 kHz的窄带话音或者采样频率为16 kHz的宽带话音。
3. T/F编码器
使用时间-频率(time-to-frequency,T/F)技术。这是一种使用矢量量化(vector quantization,VQ)和线性预测的编码器,压缩之后输出的数据率大于16 kb/s,用于采样频率为8 kHz的声音信号。
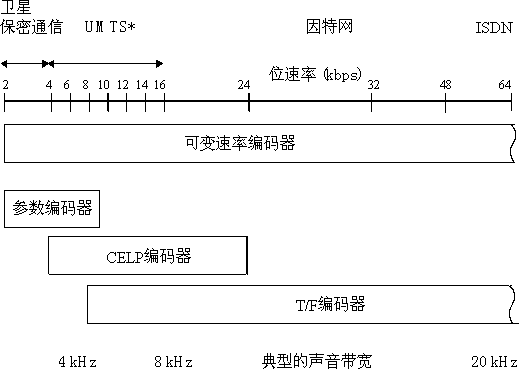
* UMTS (universal mobile telecommunication system) 通用移动远程通信系统
图4-26 MPEG-4 Audio编码方框图
2 合成声音
MPEG-4的译码器支持合成乐音和TTS声音。合成乐音通常叫做MIDI(Musical Instrument Data Interface)乐音,这种声音是在乐谱文件或者描述文件控制下生成的声音,乐谱文件是按时间顺序组织的一系列调用乐器的命令,合成乐音传输的是乐谱而不是声音波形本身或者声音参数,因此它的数据率可以相当低。随着科学技术突飞猛进的发展,尤其是网络技术的迅速崛起和飞速发展,文-语转换TTS(text to speech)系统在人类社会生活中有着越来越广泛的应用前景,已经逐渐变成相当普遍的接口,并且在各种多媒体应用领域开始扮演重要的角色。TTS编码器的输入可以是文本或者带有韵律参数的文本,编码器的输出数据率可以在200 bps ~ 1.2 kb/s范围里。
1. MIDI合成声音
MIDI是1983年制定的乐器和计算机的标准语言,是一套指令即命令的约定,它指示乐器即MIDI设备要做什么和怎么做,如播放音符、加大音量、生成音响效果等。MIDI不是声音信号,在MIDI电缆上传送的不是声音,而是发给MIDI设备或其它装置让它产生声音或执行某个动作的指令。由于MIDI具有控制设备的功能,因此它不仅用于乐器,而且越来越多的应用正在被发掘。有关MIDI的详细介绍请读者参阅第八章。
2. 文-语转换
文-语转换是将文本形式的信息转换成自然语音的一种技术,其最终目标是使计算机输出清晰而又自然的声音,也就是说,要使计算机像人一样,根据文本的内容可带各种情调来朗读任意的文本。TTS是一个十分复杂的系统,涉及到语言学、语音学、信号处理、人工智能等诸多的学科。
由于TTS系统具有巨大的应用潜力和商业价值,许多研究机构都在从事这方面的研究。目前的TTS系统一般能够较为准确清晰地朗读文本,但是不太自然。TTS系统最根本的问题便在于它的自然度,自然度是衡量一个TTS系统好坏的最重要指标。人们是无法忍受与自然语音相差甚远的语音,自然度问题已经成为严重阻碍TTS系统的推广和应用的桎梏。因此,研究更好的文语转换方法,提高合成语音的自然度就成为当务之急。
一个相当完整的TTS系统如图4-27所示。尽管现有的TTS系统结构各异,转换方法不同,但是基本上可以分成两个相对独立的部分。在图中,虚线左边的部分是文本分析部分,通过对输入文本进行词法分析、语法分析,甚至语义分析,从文本中抽取音素和韵律等发音信息。虚线右边的部分是语音合成部分,它使用从文本分析得到的发音信息去控制合成单元的谱特征(音色)和韵律特征(基频、时长和幅度),送入声音合成器(软件或硬件)产生相应的语音输出。
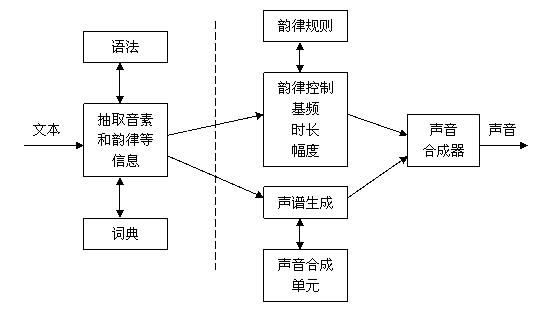
图4-27 TTS系统方框图
在汉语TTS系统中,汉语语音的传统分析方法是将一个汉语的音节分为声母和韵母两部分。声母是音节开头的辅音,韵母是音节中声母以外的部分。声母不等同于辅音,韵母不等同于元音。另外,音调具有辨义功能,这也是汉语语音的一大特点。
汉语的音节一般由声母、韵母和声调三部分组成。汉语有21个声母,39个韵母,4个声调。共能拼出400多个无调音节,1200多个有调音节。除个别情况外,一个汉字就是一个音节,但是一个音节往往对应多个汉字,这就是汉语中的多音字现象。汉字到其发音的转换一般可以借助一张一一对应的表来实现,但对多音字的读音,一般要依据它所在的词来判断,有的还要借助语法甚至语义分析,依据语义或者上下文来判断。在汉语TTS系统中,分词是基础,只有分词正确,才有可能正确地给多音字注音,正确地进行语法分析,获得正确的读音和韵律信息。
在我国,许多高等院校和科研单位先后开展了对汉语TTS系统的研究工作,并取得了可喜的成绩,但在合成声音的自然度方面还有一段漫长的路要走。清华大学计算机系“智能技术与系统国家重点实验室”在20世纪90年代末期也加强了对汉语TTS的研究工作,从语言学、语音学、信号处理和人工智能等方面进行综合研究,重点是提高汉语TTS系统输出的声音的自然度。